Source: The Conversation – Canada – By Omid Haeri Ardakani, Research scientist at Natural Resources Canada; Andjunct associate professor, University of Calgary
Hydrogen resources have long been a multi-billion-dollar market, even before recent interest in hydrogen as a contributor to the green energy transition. The environments and conditions that result in natural hydrogen accumulation occur globally. But one of the barriers to investment in many jurisdictions is regulatory, as hydrogen had not previously been considered as a resource.
Natural hydrogen can be used to decarbonize hard-to-abate but globally critical industries. Industries that use hydrogen include fuel refining (about 44 per cent), ammonia and fertilizer production for food sustainability (about 34 per cent), and steel manufacturing (about five per cent).
According to a recent British government policy briefing document, addressing this requires governments to include hydrogen as a listed natural resource. Future uses for hydrogen may include long-distance transportation and contributions to the decarbonization of the mining industry.
High carbon footprint
Most of the hydrogen used today is produced from fossil fuels. Because of this, hydrogen production contributes about 2.5 per cent of global carbon dioxide emissions. Efforts to produce low-carbon (green) hydrogen from renewable electricity and carbon capture and storage technologies remain expensive.
Developing strategies could determine whether hydrogen from any source is an economically viable resource. For natural hydrogen, exploration strategies have to be developed to find and extract natural deposits of hydrogen at an economically feasible cost. This also needs incentives that include natural hydrogen in exploration or production licenses.
An unusual coincidence sparked the current global interest in hydrogen. An accidental discovery of the small natural hydrogen gas field in Mali coincided with the publication of extensive historical data from the former Soviet Union, drawing attention to hydrogen’s immense potential as a clean power resource. Australia, France and the U.S. were among the first countries to re-investigate historical natural hydrogen.
Natural hydrogen and helium systems have similarities to petroleum systems, requiring a source rock, a migration pathway and accumulation in a reservoir. The infrastructure for natural hydrogen wells would be comparable to hydrocarbon wells, albeit with changes in well completion and drilling methods.
The footprint of a natural hydrogen production project would take up much less space to deliver the same amount of energy compared to a green hydrogen production facility, which requires solar or wind farms and electrolyzers.
Similarly, natural hydrogen projects do not need to draw on surface water resources, which are scarce in many parts of the world.
Some jurisdictions lack policies regulating hydrogen exploration. In others, regulation falls under existing mining or hydrocarbon policies. The lack of clear regulations in areas with high potential for natural hydrogen exploration — such as the U.S., Canada, India and parts of Africa and Europe — is a major obstacle for exploration.
An absence of regulation slows down exploration and land acquisition, and prevents the decision-making required for developing infrastructure. And critically, it means that no community consultations are undertaken to ensure the social acceptance essential for the success of such projects.
A project in South Australia demonstrates what legislation can accomplish. Once regulation of natural hydrogen exploration and capture was implemented, the government received dozens of applications from companies interested in natural hydrogen exploration.
The appetite for exploration is clearly there, but policy and regulatory solutions are required. New exploration projects will provide critical new data to understand natural hydrogen’s potential to provide green energy.
Omid Haeri Ardakani has received funding from Natural Resources Canada (NRCan).
Barbara Sherwood Lollar receives funding from the Natural Sciences and Engineering Research Council of Canada and the Nuclear Waste Management Organization.
Chris Ballentine is founder of and owns shares in Snowfox Discovery Ltd, a hydrogen exploration company. He receives research funding from the Natural Environment Research Council (U.K.) and the National Science Foundation (U.S.), in a joint grant, as well as the Canadian Nuclear Waste Management Organization and the Canadian Institute For Advanced Research.
Source: The Conversation – Africa (2) – By Burtram C. Fielding, Dean Faculty of Sciences and Professor in the Department of Microbiology, Stellenbosch University
Millions of people who recover from infections like COVID-19, influenza and glandular fever are affected by long-lasting symptoms. These include chronic fatigue, brain fog, exercise intolerance, dizziness, muscle or joint pain and gut problems. And many of these symptoms worsen after exercise, a phenomenon known as post-exertional malaise.
Medically the symptoms are known as myalgic encephalomyelitis or chronic fatigue syndrome (ME/CFS). The World Health Organization classifies this as a post viral fatigue syndrome, and it is recognised by both the WHO and the United States Centers for Disease Control and Prevention as a brain disorder.
Experiencing illness long after contracting an infection is not new, as patients have reported these symptoms for decades. But COVID-19 has amplified the problem worldwide. Nearly half of people with ongoing post-COVID symptoms – a condition known as long-COVID – now meet the criteria for ME/CFS. Since the start of the pandemic in 2020, it is estimated that more than 400 million people have developed long-COVID.
To date, no widely accepted and testable mechanism has fully explained the biological processes underlying long-COVID and ME/CFS. Our work offers a new perspective that may help close this gap.
Our research group studies blood and the cardiovascular system in inflammatory diseases, as well as post-viral conditions. We focus on coagulation, inflammation and endothelial cells. Endothelial cells make up the inner layer of blood vessels and serve many important functions, like regulating blood clotting, blood vessel dilation and constriction, and inflammation.
Our latest review aims to explain how ME/CFS and long-COVID start and progress, and how symptoms show up in the body and its systems. By pinpointing and explaining the underlying disease mechanisms, we can pave the way for better clinical tools to diagnose and treat people living with ME/CFS and long-COVID.
What is endothelial senescence?
In our review, our international team proposes that certain viruses drive endothelial cells into a half-alive, “zombie-like” state called cellular senescence. Senescent endothelial cells stop dividing, but continue to release molecules that awaken and confuse the immune system. This prompts the blood to form clots and, at the same time, prevent clot breakdown, which could lead to the constriction of blood vessels and limited blood flow.
By placing “zombie” blood-vessel cells at the centre of these post-viral diseases, our hypothesis weaves together microclots, oxygen debt (the extra oxygen your body needs after strenuous exercise to restore balance), brain-fog, dizziness, gut leakiness (a digestive condition where the intestinal lining allows toxins into the bloodstream) and immune dysfunction into a single, testable narrative.
From acute viral infection to ‘zombie’ vessels
Viruses like SARS-CoV-2, Epstein–Barr virus, HHV-6, influenza A, and enteroviruses (a group of viruses that cause a number of infectious illnesses which are usually mild) can all infect endothelial cells. They enable a direct attack on the cells that line the inside of blood vessels. Some of these viruses have been shown to trigger endothelial senescence.
Multiple studies show that SARS-CoV-2 (the virus which causes COVID-19 disease) has the ability to induce senescence in a variety of cell types, including endothelial cells. Viral proteins from SARS-CoV-2, for example, sabotage DNA-repair pathways and push the host cell towards a senescent state, while senescent cells in turn become even more susceptible to viral entry. This reciprocity helps explain why different pathogens can result in the same chronic illness. Influenza A, too, has shown the ability to drive endothelial cells into a senescent, zombie-like state.
What we think is happening
We propose that when blood-vessel cells turn into “zombies”, they pump out substances that make blood thicker and prone to forming tiny clots. These clots slow down circulation, so less oxygen reaches muscles and organs. This is one reason people feel drained.
During exercise, the problem worsens. Instead of the vessels relaxing to allow adequate bloodflow, they tighten further. This means that muscles are starved of oxygen and patients experience a crash the day after exercise. In the brain, the same faulty cells let blood flow drop and leak, bringing on brain fog and dizziness.
In the gut, they weaken the lining, allowing bits of bacteria to slip into the bloodstream and trigger more inflammation. Because blood vessels reach every corner of the body, even scattered patches of these “zombie” cells found in the blood vessels can create the mix of symptoms seen in long-COVID and ME/CFS.
Immune exhaustion locks in the damage
Some parts of the immune system kill senescent cells. They are natural-killer cells, macrophages and complement proteins, which are immune molecules capable of tagging and killing pathogens. But long-COVID and ME/CFS frequently have impaired natural-killer cell function, sluggish macrophages and complement dysfunction.
Senescent endothelial cells may also send out a chemical signal to repel immune attack. So the “zombie cells” actively evade the immune system. This creates a self-sustaining loop of vascular and immune dysfunction, where senescent endothelial cells persist.
In a healthy person with an optimally functioning immune system, these senescent endothelial cells will normally be cleared. But there is significant immune dysfunction in ME/CFS and long-COVID, and this may enable the “zombie cells” to survive and the disease to progress.
Where the research goes next
There is a registered clinical trial in the US that is investigating senescence in long-COVID. Our consortium is testing new ways to spot signs of ageing in the cells that line our blood vessels. First, we expose healthy endothelial cells in the lab to blood from patients to see whether it pushes the cells into a senescent, or “zombie,” state.
At the same time, we are trialling non‑invasive imaging and fluorescent probes that could one day reveal these ageing cells inside the body. In selected cases, tissue biopsies may later confirm what the scans show. Together, these approaches aim to pinpoint how substances circulating in the blood drive cellular ageing and how that, in turn, fuels disease.
Our aim is simple: find these ageing endothelial cells in real patients. Pinpointing them will inform the next round of clinical trials and open the door to therapies that target senescent cells directly, offering a route to healthier blood vessels and, ultimately, lighter disease loads.
Burtram C. Fielding works for Stellenbosch University. He has received funding from the National Research Foundation, South Africa and the Technology Innovation Agency.
Resia Pretorius is a Distinguished Research Professor at Stellenbosch University and receives funding from Balvi Research Foundation and Kanro Research Foundation. She is also affiliated with University of Liverpool as a Honorary Professor. Resia is a founding director of the Stellenbosch University start-up company, Biocode Technologies and has various patents related to microclot formation in Long COVID.
Massimo Nunes receives funding from Kanro Research Foundation.
Populism is rife in various African countries. This political ideology responds to and takes advantage of a situation where a large section of people feels exploited, marginalised or disempowered. It sets up “the people” against “the other”. It promises solidarity with the excluded by addressing their grievances. Populism targets broad social groups, operating across ethnicity and class.
But how does populism fare when it informs state interventions to address long-standing societal issues under capitalism? Do populist state measures – especially when launched by a politically powerful leader – deliver improvements for the stated beneficiaries?
As academics who have researched populism for years, we were interested in the implementation and outcomes of such policies and programmes. To answer these questions, we analysed a populist intervention by President Yoweri Museveni in Uganda to address rampant land conflicts. In 2013 he set out to halt land evictions.
What good came of this? Did it help the poor?
We analysed land laws, court cases, government statements and media reports and found that, for the most part, the intervention offered short-term relief. Some people returned to the land, but the underlying land conflict was unresolved.
This created problems that continue to be felt today, including land disputes and land tenure insecurity. The intervention also increased the involvement of the president and his agents personally in providing justice.
It didn’t make pro-poor structural changes to address the root of the problem.
Yet, the intervention had several political benefits:
it enhanced the political legitimacy of the president and state
it offered a politically useful response to a land-related crisis and conflict
it addressed broader criticisms over injustice and poverty by sections of the public and opposition leaders, some of whom (like Robert Kyagulanyi) also relied on populist rhetoric.
The promise to deal with land evictions “once and for all” has yet to be realised over a decade later. During Heroes Day celebrations on 9 June 2024, Museveni’s speech repeated his promise to stop evictions.
Such promises of getting a grip on and ending evictions via decisive state actions, including proposed new legal guidelines, were also made more recently, for example during Heroes Day 2025. This indicates that evictions – and state responses to them – remain a top issue on the political agenda ahead of Uganda’s 2026 election.
Persistent evictions
Evictions were rampant in the 2010s, especially in central Uganda’s Buganda region. They were driven by increased demand for land amid a growing population and legal reforms that seemed to protect tenants over landlords. Some landlords, desperate to free their land of tenants, were carrying out the evictions themselves.
In response, Museveni set up a land committee within the presidency. He announced at a press conference in early 2013 that:
all evictions are halted. There will be no more evictions, especially in the rural areas. All evictions involving peasants are halted.
The dynamics of populism-in-practice
Museveni’s attempts to personally deal with evictions illustrate a continued power shift in Uganda, from institutions to the president’s executive units.
Despite its shortcomings, such as case backlogs, the judicial system offers an opportunity to present cases in a more neutral environment. It also allows parties to appeal decisions. This way, higher courts can correct errors where necessary.
The presidential land committee, we found, tended to be biased in favour of tenants, paying less attention to the landlords’ cases.
The president’s intervention wasn’t adequate to address the immediate causes and effects of the evictions, nor the root causes.
Those included land tenure insecurities. Due to legal reforms, land-rich landlords were unable to get rent at market value from tenants. Neither could they evict them lawfully where rent was in arrears.
In some cases, legal options such as land sales between landlords and tenants were applied. This was often to the detriment of tenants, especially where there was no neutral actor to oversee negotiations.
Land reforms need to be institutionalised and funded to deliver the intended outcomes. Otherwise, unlawful sales and evictions become a quick option for landlords.
Museveni’s populist initiative also unleashed new problems for beneficiaries. Some secured land occupancy in the interim but lived in fear of a relapse of conflict. Mistrust and scarred interpersonal relationships hampered cohesion in some communities. Disputes over land put political actors who would ideally be working together to restore calm at loggerheads.
Populism as power
The creation of populist presidential units has become routine in Uganda. More recently, Museveni created a unit to protect investors, which has resolved some investment-related land disputes. Another one was established to fight corruption. Both units remain very active.
Our research finds that the government needs these units and interventions for a number of reasons. It uses them to govern the country’s conflict-ridden economy and society. They allow the government to assemble a politically useful response to crises and to address some on-the-ground problems. They make the state look concerned and responsive to people’s needs. And they allow ruling party political actors to increase their popularity locally.
Museveni and his ruling party, the National Resistance Movement, therefore, benefit from a key aspect of populism. It allows the merging of disparate, competing and contradictory views, interests and demands of members of various societal classes and groups into a significantly simplified and uniform narrative that (potentially) speaks to all. This could mean: end corruption, end evictions, wealth for all, and so on.
A general election is due in early 2026. The steps Museveni has taken on evictions, and the units set up to fight corruption or protect investors, need to be seen with this political context in mind.
Museveni has put protecting people from evictions high on his government’s agenda. Speaking to party members in August 2024, he emphasised
the importance of adhering to the mass line, which prioritises the needs and rights of the masses over those of the elite.
In our view, this pre-election narrative signifies the continued political and social relevance of populism in today’s Uganda. This could result in heightened populist state activity in the run-up to and after the election.
The authors do not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and have disclosed no relevant affiliations beyond their academic appointment.
Democratic consolidation is a continuing struggle, in Africa as elsewhere. The turn to democracy gained momentum in Africa in the late 1980s and early 1990s but has petered out since. Can new generations turn the tide?
The need to prepare young people to become democratically minded is well established. In western societies, school-based civic education has been considered the means to do it since as early as the 1960s. The assumption is that better knowledge about the democratic functioning of the state promotes stronger democratic values and norms. It is also thought to increase trust in institutions and a willingness to participate in politics in the future.
Research in western settings indeed shows that classroom instruction strengthens political attitudes and behaviour. Yet can we expect civic education to work in the same way in newer democracies? In weak democracies studies have found that civic education could actually lead young people away from political participation. Young people may become more aware of the flaws of their own system and turn away from politics.
Nigeria made the move from military rule to multiparty democracy in 1999 but remains a flawed democracy struggling with political corruption, vote buying and episodic violence. Individual liberties are only weakly protected.
As Africa’s most populous democracy, with a big young population, Nigeria needs young people to participate in democratic politics. And they have done so, as can be seen from events like the #EndSARS protests. Nevertheless many youths also show voter apathy. Or they engage in the country’s well-known cycles of election violence.
As scholars, we have conducted extensive research on how young people in African countries can overcome some dark legacies, like violent conflict, ethnic tensions and authoritarianism. In a recent study, we focused on democratic engagement among young Nigerians and how formal education could strengthen it.
Our research among secondary school students in Lagos state shows promising results. A survey of over 3,000 final year students found that those with greater political knowledge and stronger democratic values were more likely to express intent to vote, contact officials, or protest in the future.
However, these same students rejected party membership and campaigning, which are commonly associated with corruption and violence in Nigeria. In contrast, students with lower levels of knowledge and democratic values remained inclined to participate in party activities. This might be to gain economic benefits.
These findings show that the core objectives of civic education are not likely to lead youth to abandon democratic politics. Fostering knowledge about how the system (ideally) works and strengthening democratic attitudes remains a valuable approach to achieving democracy.
Our findings
Ten years after the transition from military to democratic rule, the Nigerian government made civic education mandatory in primary and secondary schools. The curriculum covers issues such as Nigeria’s independence, the structures of the state, civic rights, political parties and national unity. It also covers corruption and clientelism (the exchange of political support for economic benefits).
After learning how the government works and gaining awareness of civic rights and responsibilities, would young Nigerians remain committed to political participation with all the country’s democratic flaws?
We conducted a survey among final year secondary school students in Lagos state in 2019. About 3,000 students across 36 randomly selected schools answered our questions. The results revealed three political participation profiles:
disengaged youth – those who do not wish to take part in any type of political activity
non-party activists – intent on voting, contacting politicians or officials and protesting, but they reject party membership and campaigning
party activists – interested in joining a political party and campaigning as well as voting, contacting politicians or officials and protesting.
Disengaged youths tended to come from richer socio-economic backgrounds. They showed low trust in institutions. Non-party activists were more informed and held stronger democratic values than party activists. This is likely because they saw political parties as corrupt or violent.
In a democracy where party politics are often tainted by corruption, the youths’ selective engagement may be a sign not of apathy but of a thoughtful and principled rejection of flawed party politics.
Despite a growing distrust in political parties, civic education does not appear to discourage pro-democratic political behaviour overall.
A ‘reverse’ participation gap
Schools are not the only shapers of youths’ political behaviour. Caregivers and peers play a role. In a large number of countries, youth from richer socio-economic backgrounds are more politically informed, more trusting of institutions, and active. This results in a so-called participation gap between richer and poorer citizens.
Where democracy is yet to take root, research shows that middle- and higher-middle class citizens also have higher levels of knowledge and stronger democratic norms. But they have lower levels of institutional trust and are less likely to participate in institutional politics. This presents a “reverse” participation gap, so to speak.
In our research, we found partial evidence of this “reverse participation gap”. Students from wealthier backgrounds were less likely to participate, but not necessarily because they had stronger democratic norms. One possible explanation is that these students were less economically dependent on the state. With no need to rely on public institutions for jobs or welfare, they might feel less of a need to engage with them.
Retreat from political participation
In non-established democracies, research shows that more educated citizens often are more critical of their governments. In Ghana and Zimbabwe, these citizens were less likely to participate in elections.
Concerning civic education programmes specifically, an intervention in the Democratic Republic of Congo showed that these programmes might increase political knowledge and commitment to democratic values, but also decrease satisfaction with democracy in their country.
School-based research from the continent is lacking. But studies examining school-based civic education in electoral democracies elsewhere also show a retreat from institutionalised political participation. This spans voting, party membership, campaigning, and contacting politicians.
Our study finds more optimistic results for civic education programmes in Africa. Youths with high knowledge and values – the core objectives of civic education – remain committed to democratic political behaviour.
Leila Demarest receives funding from Leiden University Fund (grant reference W19304-5-01).
Line Kuppens does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation – Africa (2) – By Oluwafemi Adebo, Professor of Food Technology and Director of the Centre for Innovative Food Research (CIFR), University of Johannesburg
Would you eat food that was printed by a machine? 3D printed food is built up by equipment (a 3D food printer), layer after layer, using edible pastes, dough and food slurries in three-dimensional forms. These machines use digital models to produce precise, often personalised food items. Most 3D printed foods are made from nutrient-dense sources (plant and animal), which means they can offer health benefits.
The global market for 3D printed food is growing. It’s been estimated as worth US$437 million in 2024 and projected to reach US$7.1 billion in 2034. But the concept is still emerging in Africa.
Food science and technology researcher Oluwafemi Ayodeji Adebo and marketing academic Nicole Cunningham share what they learnt from a survey about South African consumers’ feelings on the subject.
How is food 3D printed and why?
In 3D food printing, edible food materials are formulated into printable materials (food ink). These inks can be made from pureed vegetables, doughs, or nutrient-rich mixes. The food ink is loaded into a 3D printer and extruded in layers until the selected shape is complete.
After printing, some products are ready to eat, while others need further processing such as baking or freeze-drying. The most common method is extrusion-based printing, valued for its simplicity and versatility.
The technique enables the customisation of food. Meals can be highly personalised in texture, appearance and nutritional content.
It can also transform food waste into food products. For example it can turn imperfect broccoli and carrots into healthy snacks and make noodles from potato peels.
It’s also useful in texture-modified diets for people with swallowing difficulties (dysphagia), especially the elderly. The products available for these patients tend to be bland and unappealing meals such as mashed potato, pumpkin and soft porridge. 3D food printing can produce nutritionally dense meals that are easier to eat and more appetising.
Food ink can combine various sources with different nutrients to boost the health benefits. Not having to process the product with heat can also result in higher nutritional content.
In South Africa, what sorts of foods might be 3D printed?
Virtually any edible material could be transformed into food inks, although some might require additives to make them printable. The abundance of nutrient-dense and health-promoting food crops in South Africa presents an excellent opportunity for 3D food printing to create novel food.
Sorghum, cowpea and quinoa have been used to make 3D printed biscuits, for example. They are more nutritious than wheat and don’t contain gluten.
3D food printing is still in its infancy in South Africa, compared to developed countries such as China, Japan, the US and some European countries. The best-known companies that have adopted this technology include BluRhapsody, based in Italy, which makes 3D-printed pasta, and Open Meals based in Japan, which specialises in personalised sushi.
We carried out a study to understand South African consumers’ attitudes toward 3D-printed foods. Although the technology is not yet in wide use, we found some consumers were fairly knowledgeable about these foods and the associated benefits. These findings lay the foundation for business opportunities to commercialise and market 3D printed products in the region.
Who did you ask about it in your study?
The study surveyed South African consumers aged 18-65 who were familiar with the concept of 3D-printed food. We collected 355 responses, mostly females aged 24 to 44. They provided information and opinions on several aspects, including:
their awareness of 3D-printed food
their familiarity with 3D-printed food
their food neophobia (fear of new foods)
the convenience that 3D-printed food offers
their perspective on their health needs
the perceived benefits that 3D-printed food offers
attitudes towards 3D-printed food.
What did they say?
Positive attitudes were strongest among those who recognised the convenience and health-related benefits of this new technology. The potential to reduce waste, customise nutrition, and simplify meal preparation stood out as key motivators.
Interestingly, food familiarity didn’t play a significant role in people’s responses. This means they aren’t necessarily clinging to traditional or childhood meals when forming attitudes about 3D-printed food.
In short, novelty alone isn’t a deal-breaker, it’s more about perceived safety, usefulness, and understanding the benefits.
What does this tell us?
The findings highlight the crucial role of consumer education and awareness in shaping attitudes toward 3D-printed food. While unfamiliarity with the technology can create some hesitation, the research shows that consumers are not necessarily resistant to innovation. They just need to understand it better and be educated about the benefits it offers.
If food manufacturers and marketers invest in increasing public knowledge and offering hands-on experiences such as tastings, demonstrations, or transparent production processes, then consumer attitudes could shift positively.
This approach has shown promise in other markets. For example, educational campaigns in Europe and the US around lab-grown meat and plant-based proteins have improved public perception over time.
Marketers should talk about safety, health and sustainability, and demystify the technology through clear, engaging messaging. In countries where such strategies have been used, consumers have shown increased willingness to try novel food technologies. This is significant because of predicted growth in the industry.
If South African consumers see 3D-printed food more positively, this innovation could unlock opportunities to enhance food security, address malnutrition, and support personalised dietary solutions.
Oluwafemi Adebo received funding for this project from the National Research Foundation (NRF) of South Africa Support for Rated and Unrated Researchers (grant number: SRUG2204285188), the University of Johannesburg and Faculty of Science Research Committee Grant, and the South African Medica lResearch Council (SAMRC) Self-Initiated Research (SIR) Grant.
Nicole Cunningham receives funding from the DHET in order to conduct academic research.
For most of the past decade, forecasters have been able to use satellites to track these smoke plumes, but the view was only two-dimensional: The satellites couldn’t determine how close the smoke was to Earth’s surface.
The altitude of the smoke matters.
If a plume is high in the atmosphere, it won’t affect the air people breathe – it simply floats by far overhead.
But when smoke plumes are close to the surface, people are breathing in wildfire chemicals and tiny particles. Those particles, known as PM2.5, can get deep into the lungs and exacerbate asthma and other respiratory and cardiac problems.
An animation on May 30, 2025, shows a thick smoke plume from Canada moving over Minnesota, but the air quality monitors on the ground detected minimal risk, suggesting it was a high-level smoke plume. NOAA NESDIS Center for Satellite Applications and Research
The Environmental Protection Agency uses a network of ground-based air quality monitors to issue air quality alerts, but the monitors are few and far between, meaning forecasts have been broad estimates in much of the country.
Now, a new satellite-based method that I and colleagues at universities and federal agencies have been working on for the past two years is able to give scientists and air quality managers a 3D picture of the smoke plumes, providing detailed data of the risks down to the neighborhood level for urban and rural areas alike.
Data from the TEMPO satellite shows the height of the smoke plume, measured in kilometers. Light blue areas are closest to the ground, suggesting the worst air quality. Pink areas suggest the smoke is more than 2 miles (3.2 kilometers) above the ground, where it poses little risk to human health. The data aligns with air monitor readings taken on the ground at the same time. NOAA NESDIS Center for Satellite Applications and Research
TEMPO makes it possible to determine a smoke plume’s height by providing data on how much the oxygen molecules absorb sunlight at the 688 nanometer wavelength. Smoke plumes that are high in the atmosphere reflect more solar radiation at this wavelength back to space, while those lower in the atmosphere, where there is more oxygen to absorb the light, reflect less.
Understanding the physics allowed scientists to develop algorithms that use TEMPO’s data to infer the smoke plume’s altitude and map its 3D movement in nearly real time.
Aerosol particles in high smoke plumes reflect more light back into space. Closer to Earth’s surface, there is more oxygen to absorb light at the 688 nanometer wavelength, so less light is reflected. Satellites can detect the difference, and that can be used to determine the height of the smoke plume. Adapted from Xu et al, 2019, CC BY
By combining TEMPO’s data with measurements of particles in the atmosphere, taken by the Advanced Baseline Imager on the NOAA’s GOES-R satellites, forecasters can better assess the health risk from smoke plumes in almost real time, provided clouds aren’t in the way.
That’s a big jump from relying on ground-based air quality monitors, which may be hundreds of miles apart. Iowa, for example, had about 50 air quality monitors reporting data on a recent day for a state that covers 56,273 square miles. Most of those monitors were clustered around its largest cities.
NOAA’s AerosolWatch tool currently provides a near-real-time stream of wildfire smoke images from its GOES-R satellites, and the agency plans to incorporate TEMPO’s height data. A prototype of this system from my team’s NASA-supported research project on fire and air quality, called FireAQ, shows how users can zoom in to the neighborhood level to see how high the smoke plume is, however the prototype is currently only updated once a day, so the data is delayed, and it isn’t able to provide smoke height data where clouds are also overhead.
While air quality in most of the U.S. improved between 2000 and 2020, thanks to stricter emissions regulations on vehicles and power plants, wildfires have reversed that trend in parts of the western U.S. Research has found that wildfire smoke has effectively erased nearly two decades of air quality progress there.
Our advances in smoke monitoring mark a new era in air quality forecasting, offering more accurate and timely information to better protect public health in the face of these escalating wildfire threats.
Prof. Wang’s group have been supported from NOAA, NASA, and Naval ONR to develop research algorithm to retrieve aerosol layer height. The compute codes of the research algorithm were shared with colleagues in NOAA.
Black soldier fly maggots can feed on decomposing animals. Melanie M. Beasley
Scientists long thought that Neanderthals were avid meat eaters. Based on chemical analysis of Neanderthal remains, it seemed like they’d been feasting on as much meat as apex predators such as lions and hyenas. But as a group, hominins – that’s Neanderthals, our species and other extinct close relatives – aren’t specialized flesh eaters. Rather, they’re more omnivorous, eating plenty of plant foods, too.
It is possible for humans to subsist on a very carnivorous diet. In fact, many traditional northern hunter–gatherers such as the Inuit subsisted mostly on animal foods. But hominins simply cannot tolerate consuming the high levels of protein that large predators can. If humans eat as much protein as hypercarnivores do over long periods without consuming enough other nutrients, it can lead to protein poisoning – a debilitating, even lethal condition historically known as “rabbit starvation.”
So, what could explain the chemical signatures found in Neanderthal bones that seem to suggest they were healthily eating tons of meat?
I am an anthropologist who uses elements such as nitrogen to study the diets of our very ancient ancestors. New researchmycolleagues and I conducted suggests a secret ingredient in the Neanderthal diet that might explain what was going on: maggots.
The ratios of various elements in the bones of animals can provide insights into what they ate while alive. Isotopes are alternate forms of the same element that have slightly different masses. Nitrogen has two stable isotopes: nitrogen-14, the more abundant form, and nitrogen-15, the heavier, less common form. Scientists denote the ratio of nitrogen-15 to nitrogen-14 as δ¹⁵N and measure it in a unit called permil.
As you go higher up the food chain, organisms have relatively more of the isotope nitrogen-15. Grass, for example, has a very low δ¹⁵N value. An herbivore accumulates the nitrogen-15 that it consumes eating grass, so its own body has a slightly higher δ¹⁵N value. Meat-eating animals have the highest nitrogen ratio in a food web; the nitrogen-15 from their prey concentrates in their bodies.
By analyzing stable nitrogen isotope ratios, we can reconstruct the diets of Neanderthals and early Homo sapiens during the late Pleistocene, which ran from 11,700 to 129,000 years ago. Fossils from various sites tell the same story – these hominins have high δ¹⁵N values. High δ¹⁵N values would typically place them at the top of the food web, together with hypercarnivores such as cave lions and hyenas, whose diet is more than 70% meat.
But maybe something else about their diet was inflating Neanderthals’ δ¹⁵N values.
Uncovering the Neanderthal menu
We suspected that maggots could have been a different potential source of enriched nitrogen-15 in the Neanderthal diet. Maggots, which are fly larvae, can be a fat-rich source of food. They are unavoidable after you kill another animal, easily collectible in large numbers and nutritionally beneficial.
To investigate this possibility, we used a dataset that was originally created for a very different purpose: a forensic anthropology project focused on how nitrogen might help estimate time since death.
I had originally collected modern muscle tissue samples and associated maggots at the Forensic Anthropology Center at University of Tennessee, Knoxville, to understand how nitrogen values change during decomposition after death.
While the data can assist modern forensic death investigations, in our current study we repurposed it to test a very different hypothesis. We found that stable nitrogen isotope values increase modestly as muscle tissue decomposes, ranging from -0.6 permil to 7.7 permil.
This increase is more dramatic in maggots feeding on decomposing tissue: from 5.4 permil to 43.2 permil. To put the maggot values in perspective, scientists estimate δ¹⁵N values for Pleistocene herbivores to range between 0.9 permil to 11.2 permil. Maggots are measuring up to almost four times higher.
Our research suggests that the high δ¹⁵N values observed in Late Pleistocene hominins may be inflated by year-round consumption of ¹⁵N-enriched maggots found in dried, frozen or cached animal foods.
Cultural practices shape diet
In 2017, my collaborator John Speth proposed that the high δ¹⁵N values in Neanderthals were due to the consumption of putrid or rotting meat, based on historical and cultural evidence of diets in northern Arctic foragers.
Traditionally, Indigenous peoples almost universally viewed thoroughly putrefied, maggot-infested animal foods as highly desirable fare, not starvation rations. In fact, many such peoples routinely and often intentionally allowed animal foods to decompose to the point where they were crawling with maggots, in some cases even beginning to liquefy.
This rotting food would inevitably emit a stench so overpowering that early European explorers, fur trappers and missionaries were sickened by it. Yet Indigenous peoples viewed such foods as good to eat, even a delicacy. When asked how they could tolerate the nauseating stench, they simply responded, “We don’t eat the smell.”
Neanderthals’ cultural practices, similar to those of Indigenous peoples, might be the answer to the mystery of their high δ¹⁵N values. Ancient hominins were butchering, storing, preserving, cooking and cultivating a variety of items. All these practices enriched their paleo menu with foods in forms that nonhominin carnivores do not consume. Research shows that δ¹⁵N values are higher for cooked foods, putrid muscle tissue from terrestrial and aquatic species, and, with our study, for fly larvae feeding on decaying tissue.
The high δ¹⁵N values of maggots associated with putrid animal foods help explain how Neanderthals could have included plenty of other nutritious foods beyond only meat while still registering δ¹⁵N values we’re used to seeing in hypercarnivores.
We suspect the high δ¹⁵N values seen in Neanderthals reflect routine consumption of fatty animal tissues and fermented stomach contents, much of it in a semi-putrid or putrid state, together with the inevitable bonus of both living and dead ¹⁵N-enriched maggots.
What still isn’t known
Fly larvae are a fat-rich, nutrient-dense, ubiquitous and easily procured insect resource, and both Neanderthals and early Homo sapiens, much like recent foragers, would have benefited from taking full advantage of them. But we cannot say that maggots alone explain why Neanderthals have such high δ¹⁵N values in their remains.
Several questions about this ancient diet remain unanswered. How many maggots would someone need to consume to account for an increase in δ¹⁵N values above the expected values due to meat eating alone? How do the nutritional benefits of consuming maggots change the longer a food item is stored? More experimental studies on changes in δ¹⁵N values of foods processed, stored and cooked following Indigenous traditional practices can help us better understand the dietary practices of our ancient relatives.
Melanie Beasley received funding from the Haslam Foundation for this research.
Would you dab perfume on a six-month-old? Paint their tiny nails with polish that contains formaldehyde? Dust bronzer onto their cheeks?
An investigation by the Times has found that babies and toddlers are routinely exposed to adult cosmetic products, including fragranced sprays, nail polish and even black henna tattoos.
While these may sound harmless – or even Instagram-friendly – the science tells a more concerning story. Infant skin is biologically different from adult skin: it’s thinner, more absorbent and still developing. Exposure to certain products can lead to immediate problems like irritation or allergic reactions, and in some cases, may carry longer term health-risks such as hormone disruption.
This isn’t a new concern. A 2019 study found that every two hours in the US, a child was taken to hospital because of accidental exposure to cosmetic products.
Newborn skin has the same number of layers as adult skin but those layers are up to 30% thinner. That thinner barrier makes it easier for substances, including chemicals, to penetrate through to deeper tissues and the bloodstream.
Young skin also has a higher water content and produces less sebum (the natural oil that protects and moisturises the skin). This makes it more prone to water loss, dryness and irritation, particularly when exposed to fragrances or creams not formulated for infants.
The skin’s microbiome – its protective layer of beneficial microbes – also takes time to develop. By age three, a child’s skin finishes establishing its first microbiome. Before then, products applied to the skin can disrupt this delicate balance. At puberty, the skin’s structure and microbiome change again, altering how it responds to products.
The investigation found that bronzers and nail polish were being used on young children. These products often contain harmful or even carcinogenic chemicals, such as formaldehyde, toluene and dibutyl phthalate.
Even low-level exposure to formaldehyde, such as from furniture or air pollution, has been linked to higher rates of lower respiratory infections in children (that’s infections affecting the lungs, airways and windpipe).
Irritating ingredients
In the US, one in three adults experiences skin or respiratory symptoms after exposure to fragranced products. If adults are reacting, it’s no surprise that newborns and children with their developing immune systems are at even greater risk.
Perfumes often contain alcohol and volatile compounds that dry out the skin, leading to redness, itching and discomfort.
Certain skincare ingredients have also been studied for their potential to affect hormones, trigger allergies or pose long-term health concerns:
alkylphenols used in detergents and cosmetics may disrupt hormone activity
benzophenone is found in many sunscreens and some forms may act as allergens and hormone disruptors.
While many of these ingredients are permitted in regulated concentrations, some researchers warn of a “cocktail effect”: the cumulative impact of daily exposure to multiple chemicals, especially in young, developing bodies.
Temporary tattoos, particularly black henna, are popular on holidays but they aren’t always safe. Black henna is a common cause of contact dermatitis in children and may contain para-phenylenediamine (PPD), a chemical approved for use in hair dyes but not for direct application to skin.
Products marketed as “natural” or “clean” can also cause allergic reactions. Propolis (bee glue), for instance, is found in many natural skincare products but causes contact dermatitis in up to 16% of children.
A study found an average of 4.5 contact allergens per product in “natural” skincare ranges. Out of 1,651 “natural” personal care products on the US market, only 96 (5.8%) were free from contact allergens. Even claims like “dermatologically tested” don’t guarantee safety; they simply mean the product was tested on skin, not that it’s free from allergens.
Babies and young children aren’t just miniature adults. Their skin is still developing and is more vulnerable to irritation, chemical absorption and systemic effects: substances that penetrate the skin can enter the bloodstream and potentially affect organs or biological systems throughout the body. Applying adult-targeted products, or even well-meaning “natural” alternatives, can therefore carry real risks.
Adverse reactions can appear as rashes, scaling or itchiness and, in severe cases, blistering or crusting. Respiratory symptoms like coughing or wheezing should always be investigated by a medical professional.
When in doubt, keep it simple. Limit what goes on your child’s skin, especially in the early years.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Adam Taylor does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
The alchemist’s dream is to make gold from common metals, but can this be done?
The physics needed to explain how to change one element into another is well
understood and has been used for decades in accelerators and colliders, which smash sub-atomic particles together.
The most notable present-day example is the Large Hadron Collider at Cern, based in Geneva. But the costs of making gold this way are vast, and the quantities generated are minuscule.
For example, Cern’s Alice experiment estimated it produced only 29 picogrammes of gold while operating over four years. At that rate, it would take hundreds of times the lifetime of the universe to make a troy ounce of gold.
The Californian startup company Marathon Fusion has proposed a very different approach: to use the radioactivity from neutron particles in a nuclear fusion reactor to transform one form of mercury into another, called mercury-197.
This then decays into a stable form of gold: gold-197. This process of particle decay is where one subatomic particle spontaneously transforms into two or more lighter particles. The team from Marathon Fusion estimates that a fusion power plant could produce several tonnes of gold per gigawatt of thermal power in a single year of operation.
Bombarding the isotope mercury-198 with neutrons leads to the creation of the
radioactive isotope mercury-197 – which subsequently decays to the only stable
isotope of gold.
The key is to have energetic enough neutrons to trigger the mercury decay sequence. If this could be made to work, then it is an interesting idea. But whether it could make a tidy profit is another matter.
To do this, a large neutron flux (a measure of the intensity of neutron radiation) is required. This can be generated using a standard fuel mix for fusion reactors, deuterium and tritium (both of which are forms of hydrogen), to create energy in the plasma of a fusion reactor.
Neutrons penetrate material easily and scatter off the nuclei (cores) in atoms, slowing down as they do so. Neutrons with energies above 6 million electron volts are required to transform mercury-198 into gold.
To come up with its estimates, Marathon Fusion has been using a fusion reactor’s “digital twin” – a computer model that simulates the physics of the fusion reaction and the resulting radioactive processes. A limitation of this type of work is that the digital twin needs to be validated against a real commercial fusion reactor – but none currently exist.
There are many challenges to overcome before scientists can realise a commercial fusion reactor. These include the creation of new materials for its construction, and understanding the science required both to operate the system to continuously extract power, and to develop AI systems that can help keep the plasma fusion reaction running.
Even some of the most advanced fusion experiments, such as the UK-based JET (Joint European Torus) project, could only generate relatively small amounts of energy. However, researchers in the UK have devised a new way to shrink the size of fusion reactors by changing the way the exhaust plasma is controlled. A prototype of this novel fusion reactor concept, called Spherical Tokomak for Energy Production (Step), aims to be ready by 2040.
Radioactive waste
On paper, it is possible to make gold from mercury in a fusion reactor. However, until commercial fusion reactors are realised, the assumptions used by Marathon Fusion in its digital twin studies will remain untested.
Furthermore, any gold produced at a fusion reactor would initially be radioactive, meaning it would be classified as radioactive waste – and thus need to be managed for quite some time after production.
As nuclear and particle physicists know well, it is very easy to forget to include important physical effects and critical details when creating a digital twin of an experiment. But while the processing of that waste into usable forms of pure gold would be a further challenge to address, it will not necessarily deter long-term investors.
For now, this remains an attractive proposition on paper – but we’re still some way off from kickstarting a new kind of Californian gold rush.
Adrian Bevan does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
How much does your weight really say about your health? Probably less than you think. You could eat your five-a-day, hit the gym regularly, have textbook blood pressure and cholesterol levels – and still be dismissed as “unhealthy” based on the number on the scale. Meanwhile, someone with a so-called “healthy” weight might be skipping meals, running on stress and caffeine, and rarely moving their body.
We’ve been taught to equate thinness with wellness and excess weight with illness. But the science tells a more nuanced story – one where weight is just a single data point in a far more complex picture. So if weight alone doesn’t reflect how healthy we really are, what does?
Body weight is one of the most measured aspects of health. Society places huge emphasis on it, and criticism of a person’s weight is often framed as a health concern. So how much meaningful health information does weight actually offer?
Simply put, body weight measures exactly that – the total weight of a body. Changes in weight over time can give an indication of a person’s calorie intake. If they are gaining weight, they are eating more calories than they burn. If they are losing weight, they are burning more than they eat.
It is perhaps more useful to consider the health information weight doesn’t give us. Important health indicators, such as cholesterol, blood sugar, blood pressure and heart rate are not visible on the scales.
Neither does weight reflect the quality of someone’s diet. A person could be eating plenty of fruit, vegetables and whole foods, getting the vitamins and minerals needed for good energy, bone strength and immune function. Or they might not. They might be eating mostly healthy fats, like those found in olive oil, nuts and fish, which are linked to better heart health. Or they may get their fat from processed foods, high in saturated and trans fats, which increase the risk of heart disease. They may be getting plenty of fibre to support digestion, regulate their blood sugar and maintain healthy cholesterol, or they may be getting very little. Weight alone reveals none of these important dietary details.
Weight also doesn’t accurately reflect how much body fat someone carries, or more importantly, where that fat is located. Visceral fat (which surrounds the internal organs) is linked to a higher risk of heart disease, type 2 diabetes and some types of cancer, whereas subcutaneous fat, found just beneath the skin, poses fewer health risks .
Weight doesn’t give details about how much exercise someone does, which improves health even if it doesn’t lead to weight loss. Nor does weight reflect other major influences on health, like sleep quality or stress.
All of these factors are harder to measure than body weight, and far less visible at first glance, but they provide a much more meaningful picture of someone’s health.
This is not to say that there is no association between weight and these factors, but the link is not clear cut. Details such as someone’s diet quality or their activity patterns cannot be found by simply looking at their weight.
At a population level, there is a clear association between higher body weight and increased risk of disease. For instance, studies show that people classified as overweight or obese using body mass index (BMI), which is a measure of weight relative to height, tend to have higher rates of cardiovascular disease, type 2 diabetes and certain types of cancer.
Some people who are classified as overweight or obese have healthy blood pressure, cholesterol and blood sugar levels. This is often referred to as “metabolically healthy obesity”. On the other hand, someone with a “healthy” body weight might have high visceral fat, poor diet quality, or a sedentary lifestyle – increasing their health risks, despite appearing thin. Terms like “Tofi” (thin outside, fat inside) or “skinny-fat” have emerged to describe this.
These examples highlight how health cannot be judged accurately by weight alone. Someone eating a fibre-rich diet, high in vegetables, whole grains and healthy fats – all of which are linked to better health outcomes, might still fall into the “overweight” category, and be perceived as unhealthy simply because they eat more calories than they burn.
Conversely, a person eating a diet low in nutrients but not exceeding their calorie requirements may be considered a “healthy” weight. Which of these people would be viewed as healthy by society, and which by a doctor?
Why we think weight matters
So, why is so much emphasis put on a person’s weight? In truth, it probably shouldn’t be. However, it is a cheap and easy thing to measure, unlike blood tests, dietary assessments or body scans, which require more time, money and expertise. It’s not to say that more detailed tests are never carried out, but cost is usually a consideration.
Weight is also very visible. It is one of the few aspects of health that’s apparent to others at a glance. This makes it easy for society to pass judgement. But what is visible isn’t always what matters most. Societal ideas about what a “healthy” body looks like are deeply ingrained and not necessarily evidence based.
While losing weight as a result of healthy lifestyle modifications improves health, these modifications, such as increasing exercise and improving diet, have been shown to benefit health even if weight is not lost.
It has also been shown that the societal stigma surrounding obesity is not helpful in achieving weight loss, and can actually undermine it.
Therefore, if health really is the main concern, attention should shift away from weight as the primary focus and towards factors such as diet quality, physical activity, sleep and stress. Improvements in these areas can offer health benefits to people of all sizes.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Rachel Woods does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
There’s something oddly luxurious about a lie-in. The sun filters through the curtains, the alarm clock is blissfully silent, and your body stays at rest. Yet lie-ins are often treated as indulgences, sometimes framed as laziness or a slippery slope to soft living.
When the holidays arrive and alarm clocks are switched off, or are set later, something else emerges: your body reclaims sleep. Not just more of it, but deeper, richer and more restorative sleep. Anatomically and neurologically, a lie-in might be exactly what your body needs to recover and recalibrate.
Throughout the working year, it’s common to accumulate a chronic sleep debt – a shortfall in the sleep the body biologically needs, night after night. And the body keeps score.
On holiday, freed from early starts and late-night emails, our internal systems seize the opportunity to rebalance. It’s not uncommon to sleep an hour or two longer per night in the first few days away. That’s not laziness; it’s recovery.
Importantly, holiday sleep doesn’t just extend in duration. It shifts in structure. With fewer disturbances and less external pressure, sleep cycles become more regular, and we often experience more slow-wave sleep – the deepest phase, linked to physical healing and immune support.
The body uses this window not only to repair tissue but also to regulate metabolism, dial down inflammation and restore energy reserves.
Our sleep-wake cycle is governed by circadian rhythms, which are controlled by the brain’s master clock – the suprachiasmatic nucleus in the hypothalamus. These rhythms respond to light, temperature and routine. And when we’re overworked or overstimulated, they can drift out of sync with our environment.
A lie-in allows your circadian system to recalibrate, aligning internal time with actual daylight. This re-training leads to more coherent sleep cycles and better daytime alertness.
Holiday lie-ins also owe something to the drop in stress hormones. Cortisol, released by the adrenal glands, follows a diurnal pattern, peaking in the early morning to get us going.
Chronic stress – from work demands, commuting or constant notifications – can raise cortisol levels and disrupt this rhythm. When you take time off, cortisol production normalises. Waking up without a jolt of adrenaline allows the sleep architecture (the pattern of sleep stages) to stabilise, leading to fewer interruptions and more restful nights.
One of the more striking features of holiday sleep is a surge in vivid dreaming – sometimes unsettlingly so. This is because of a phenomenon called REM rebound. When we’re sleep-deprived, the brain suppresses REM (rapid eye movement) sleep to prioritise deep, restorative phases.
Once the pressure lifts – say, during a lazy week in the sun – the brain makes up for lost REM, leading to longer and more intense dream episodes. Far from frivolous, REM sleep is crucial for memory consolidation, mood regulation and cognitive flexibility.
Sleep also affects your body’s structure. When you lie down, your spine gets a break from the constant pressure of gravity. During the day, as you stand and move around, the intervertebral discs – soft, cushion-like pads between the vertebrae – slowly lose fluid and become slightly flatter. A lie-in gives these discs more time to rehydrate and return to their normal shape. That’s why you’re a little taller in the morning – and even more so after a long sleep.
Meanwhile, microtears in muscles, strained ligaments and overworked joints benefit from prolonged periods of cellular repair, especially during deep sleep stages.
Should we all be sleeping in every weekend? Not necessarily. While occasional lie-ins can help with recovery from acute sleep deprivation, habitual oversleeping –especially beyond nine hours a night – can be a red flag. It’s associated in some studies with higher rates of depression, heart disease and early death. Although long sleep might be a symptom, not a cause.
That said, the occasional lie-in remains anatomically restorative, especially when aligned with your body’s natural chronotype – a biological predisposition that determines when you feel most alert and when you feel naturally inclined to sleep.
Some people are naturally “larks”, who rise early and function best in the morning. Others are “owls”, who tend to feel sleepy late and wake later, with their peak cognitive and physical performance occurring in the afternoon or evening. Many fall somewhere in between.
Chronotype is governed by the same internal circadian system that regulates sleep-wake cycles, and it appears to be strongly influenced by genetics, age and light exposure. Adolescents typically have later chronotypes, while older adults often revert to earlier ones.
Crucially, chronotype doesn’t just affect sleep. It also plays a role in hormone release, body temperature, digestive timing and mental alertness throughout the day.
Conflict arises when social expectations, such as early work or school start times, force people, especially night owls, to adopt sleep-wake schedules that are out of sync with their biology. This mismatch, known as social jetlag, can lead to persistent tiredness, mood changes and even long-term health risks.
So if you find yourself sleeping in until 9 or 10am on the third day of your holiday, don’t berate yourself. Your body is taking the opportunity to repair, replenish and rebalance. The anatomical systems involved – from your brainstem to your adrenal glands, your intervertebral discs to your dream-rich REM phases – are doing what they’re designed to do when finally given the time.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Michelle Spear does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Would you dab perfume on a six-month-old? Paint their tiny nails with polish that contains formaldehyde? Dust bronzer onto their cheeks?
An investigation by the Times has found that babies and toddlers are routinely exposed to adult cosmetic products, including fragranced sprays, nail polish and even black henna tattoos.
While these may sound harmless – or even Instagram-friendly – the science tells a more concerning story. Infant skin is biologically different from adult skin: it’s thinner, more absorbent and still developing. Exposure to certain products can lead to immediate problems like irritation or allergic reactions, and in some cases, may carry longer term health-risks such as hormone disruption.
This isn’t a new concern. A 2019 study found that every two hours in the US, a child was taken to hospital because of accidental exposure to cosmetic products.
Newborn skin has the same number of layers as adult skin but those layers are up to 30% thinner. That thinner barrier makes it easier for substances, including chemicals, to penetrate through to deeper tissues and the bloodstream.
Young skin also has a higher water content and produces less sebum (the natural oil that protects and moisturises the skin). This makes it more prone to water loss, dryness and irritation, particularly when exposed to fragrances or creams not formulated for infants.
The skin’s microbiome – its protective layer of beneficial microbes – also takes time to develop. By age three, a child’s skin finishes establishing its first microbiome. Before then, products applied to the skin can disrupt this delicate balance. At puberty, the skin’s structure and microbiome change again, altering how it responds to products.
The investigation found that bronzers and nail polish were being used on young children. These products often contain harmful or even carcinogenic chemicals, such as formaldehyde, toluene and dibutyl phthalate.
Even low-level exposure to formaldehyde, such as from furniture or air pollution, has been linked to higher rates of lower respiratory infections in children (that’s infections affecting the lungs, airways and windpipe).
Irritating ingredients
In the US, one in three adults experiences skin or respiratory symptoms after exposure to fragranced products. If adults are reacting, it’s no surprise that newborns and children with their developing immune systems are at even greater risk.
Perfumes often contain alcohol and volatile compounds that dry out the skin, leading to redness, itching and discomfort.
Certain skincare ingredients have also been studied for their potential to affect hormones, trigger allergies or pose long-term health concerns:
alkylphenols used in detergents and cosmetics may disrupt hormone activity
benzophenone is found in many sunscreens and some forms may act as allergens and hormone disruptors.
While many of these ingredients are permitted in regulated concentrations, some researchers warn of a “cocktail effect”: the cumulative impact of daily exposure to multiple chemicals, especially in young, developing bodies.
Temporary tattoos, particularly black henna, are popular on holidays but they aren’t always safe. Black henna is a common cause of contact dermatitis in children and may contain para-phenylenediamine (PPD), a chemical approved for use in hair dyes but not for direct application to skin.
Products marketed as “natural” or “clean” can also cause allergic reactions. Propolis (bee glue), for instance, is found in many natural skincare products but causes contact dermatitis in up to 16% of children.
A study found an average of 4.5 contact allergens per product in “natural” skincare ranges. Out of 1,651 “natural” personal care products on the US market, only 96 (5.8%) were free from contact allergens. Even claims like “dermatologically tested” don’t guarantee safety; they simply mean the product was tested on skin, not that it’s free from allergens.
Babies and young children aren’t just miniature adults. Their skin is still developing and is more vulnerable to irritation, chemical absorption and systemic effects: substances that penetrate the skin can enter the bloodstream and potentially affect organs or biological systems throughout the body. Applying adult-targeted products, or even well-meaning “natural” alternatives, can therefore carry real risks.
Adverse reactions can appear as rashes, scaling or itchiness and, in severe cases, blistering or crusting. Respiratory symptoms like coughing or wheezing should always be investigated by a medical professional.
When in doubt, keep it simple. Limit what goes on your child’s skin, especially in the early years.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Adam Taylor does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
In-video advertisements that aim to increase ad revenue involve AI to tap into a users’ preferences. This means lots of individual videos with minor differences requiring additional processing scaled to the user’s streaming resolution.
But while Spotify used to publish data on its environmental costs, its reports have been incomplete since 2021. As American author and scholar, Shoshanna Zuboff points out in her book The Age of Surveillance Capitalism, many tech companies lack environmental accountability.
The Carbon Trust, a consultancy that helps businesses reduce their carbon footprints, works to globally promote a sustainable future and has calculated the European average carbon footprint for video streaming as producing 55g of CO₂e per hour. This CO₂e or carbon dioxide equivalent is a comparable measure of the potential effect of different greenhouse gases on the climate: 55g of CO₂e is 50 times more than audio streaming and the equivalent of microwaving four bags of popcorn.
As a music technology and AI researcher, I’m aware of the shift in responsibility that comes with Spotify’s video innovations. While companies’ significant role in generating emissions should not be diminished, the shift of responsibility fromt he platform to users and content creators means that better informed choices about their streaming devices and streaming quality settings larger screens need to be made. Streaming at higher resolutions becomes significant factors in increasing video’s carbon footprint.
This increased responsibility means that end users needs to make better informed choices about their streaming devices and streaming quality settings.
While companies’ significant role in generating emissions should not be diminished, this shift of responsibility to the end user means that larger screens and streaming at higher resolutions become significant factors in increasing video’s carbon footprint.
Location also affects how carbon emissions are managed. Germany has the largest carbon footprint for video streaming at 76g CO₂e per hour of streaming, reflecting its continued reliance on coal and fossil fuels. In the UK, this figure is 48g CO₂e per hour, because its energy mix includes renewables and natural gas, increasingly with nuclear as central to the UK’s low-carbon future. France, with a reliance on nuclear is the lowest, at 10g CO₂e per hour.
There is an absolute burden of responsibility on tech and media companies to reduce their carbon emissions and to be transparent about their efforts to do so. In fact, net zero cannot be achieved without commitments from the major technology companies, many of which are based in the US whose government has not ratified the Kyoto protocol and withdrew from the Paris agreement in 2020 which are both significant global efforts to combat climate change.
Eco-conscious music streaming
A French thinktank called the Shift Project advocates for people and companies to adopt “digital sobriety” (the mindful use of digital tech) to ensure efficiency and sustainability. For example, research shows that the UK could reduce its carbon output by more 16,433 tonnes if each adult sent one less thank you email a day.
Certainly aimless streaming should be avoided because video decoding can account for 35-50% of playback energy on user devices. However, music video is more than mere music. As I have argued in my own work, video “provides a layer of meaning making not present in lyrics or audio alone”.
Video can bring marginalised music makers, cultures and ideas to the foreground by tackling difficult subjects. Like the work of Syrian-American rapper, poet, activist and chaplain Mona Haydar’s Wrap My Hijab or UK grime rapper Drillminister and his critique of neo-liberalism and trickle-down economics Nouveau Riche.
To minimise the environmental footprint of your own music streaming, use Wi-Fi rather than 4G or 5G. If you listen to a song repeatedly, purchase a download to play. Use localised storage rather than cloud-based systems for all of your music and video files. Reduce auto-play, aimless background streaming or using streaming as a sleep aid by changing the default settings on your device including reducing streaming resolution. And turn your camera off for video calls, as carbon emissions are 25 times more than for audio only.
Don’t have time to read about climate change as much as you’d like?
Hussein Boon does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation – UK – By Benjamin Selwyn, Professor of International Relations and International Development, Department of International Relations, University of Sussex
Global supply chains account for 70% of world trade. They are the arteries of global capitalism, moving goods and services across borders multiple times before reaching consumers.
Since the early 1990s — as part of economic globalisation — these networks have enabled mass consumption by delivering cheap goods made using cheap labour and shipped globally at minimal cost. But this convenience comes at a catastrophic environmental price.
The infrastructure that supports global supply chains — ports, highways, railways, data servers — has expanded dramatically, increasing the distance goods travel from production to consumption to disposal. These “supply chain miles” are a major contributor to ecological degradation.
Worse still, managing these sprawling networks depends on energy-intensive digital technologies, produced and distributed through global supply chains. Electronic waste is soaring, reaching 62 million tonnes in 2022 and projected to increase to 82 million tonnes by 2030.
Global supply chains have also driven the expansion of global markets. Argentina’s soy industry is a case in point: production surged from under 30,000 tonnes in 1970 to over 60 million tonnes in 2015, largely to feed the world’s growing livestock population.
As an expert on global supply chains, I study what can be done to remedy this environmentally damaging situation. My research shows that this problem runs deeper than logistics.
Global supply chains are a key part of the capitalist system that thrives on endless economic growth. Competitive capital accumulation (where profits are reinvested to generate more profits) drives this cycle.
While green technologies can hypothetically make supply chains more efficient, enhanced efficiency under capitalism often leads to more production, not less. Efficiency gains can reduce costs, make goods more profitable and stimulate greater investment. Energy-saving lightbulbs and digital tools, for example, have led to broader adoption and higher overall energy use, rather than a decrease in energy demand.
Better tech alone won’t reduce environmental harm. We need a shift toward a low-energy economy that prioritises human and ecological wellbeing over profit.
Public transport, healthcare, open-source software and urban food systems are examples of social provision that are often cheaper, more inclusive and more environmentally sustainable than their profit-orientated alternatives.
Greening supply chains
I’ve identified five practical steps that can reduce the environmental footprint of supply chains.
First, accelerating the transition from fossil fuels to renewables is essential. The Danish Island of Samsø went from fossil fuel dependence to 100% renewable energy by the early 2000s in the space of a decade by constructing and deploying on- and off-shore wind-power and biomass boilers. Scaling up such transitions could power cleaner supply chain infrastructure.
Second, the electrification of shipping means that battery-powered shipping is no longer science fiction. The Yara Birkeland, the world’s first fully electric cargo ship, recently launched with a 100-container capacity. One study suggests that 40% of container traffic could be electrified this decade using existing technology.
Third, by designing for durability and repair, digital and electronic products can be built to last and easy to repair. The “right to repair” movement advocates for consumer rights to fix and repair products rather than having to buy new ones and is gaining traction.
It is challenging corporate control over who can fix what. Six US states have passed laws giving consumers the right to repair their own devices. In the UK, a community initiative called the Restart Project is pushing for stronger regulations and promoting community-based repair initiatives and digital technology sharing.
Designing products that last and can easily be repaired helps create a more circular and less wasteful economy. Natali Ximich/Shutterstock
Fourth, urban transport needs a rethink. Road transport accounts for about 12% of global greenhouse gas emissions. That sector could be streamlined by shifting supply chains from manufacturing millions of cars to investing in efficient and affordable bus, train and bike networks. Car-free cities and expanded electric public transport networks could slash emissions from road transport. This is already happening in places like Ghent in Belgium, Amsterdam in the Netherlands, Lamu Island in Kenya and Fes el Bali in Morocco.
Fifth, supply chains can be shortened by shifting diets. Reducing meat consumption could shrink the global feed-livestock chain the vast complex of animal feed production (such as soy) underpinning the burgeoning world cattle population and its associated transport emissions.
Countries such as Germany, the Netherlands and Denmark have already seen declines in meat consumption over the past decade as plant-based diets have gained popularity. The UK is also experiencing a fall in per capita meat consumption
These strategies are all tiny steps in the right direction. But, as the US author and environmentalist Bill McKibben says, “winning slowly is the same as losing”. We need much greater and more rapid transformations.
So, while parts of supply chains can become more sustainable, any efforts will be counterproductive as long as governments and firms continue chasing endless economic growth. What’s needed now is the political and cultural will to prioritise people and the planet over profit.
Don’t have time to read about climate change as much as you’d like?
Benjamin Selwyn does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
People are becoming more divided and ill informed. In January 2024, a report by the World Economic Forum identified misinformation and disinformation as “the most severe global risk anticipated over the next two years”.
As a result, it predicted “perceptions of reality are likely to also become polarised” – and that unrest resulting from unreliable information may cause “violent protests … hate crimes … civil confrontation and terrorism”. Many people would agree that something is needed to bridge the ever-widening gaps between ourselves.
In my view, this is not just a problem of alternative sets of facts, but a failure to perceive and empathise with that which is outside of our own experiences.
While the smartphone, with its capacity to provide users with sources from across the world, can provide endless opportunity to learn about other perspectives and experiences, research suggests social media increasingly cocoons users within their own interests.
This algorithmically encouraged self-importance means we are stuck in a feedback loop – the echo chamber – where our own experiences, values and desires are seen as the norm.
In contrast, by encouraging people to imagine beyond their own experience, reading poetry can serve as an exercise in seeing things from a different perspective.
Looking for something good? Cut through the noise with a carefully curated selection of the latest releases, live events and exhibitions, straight to your inbox every fortnight, on Fridays. Sign up here.
Poetry has always been political. The writer and civil-rights activist Audre Lorde argued it produces “a revelatory distillation of experience”. In other words, by distilling aspects of an experience, poetry can reveal powerful truths about reality.
Lorde’s poem Afterimages (1981) records her memory of turning 21 in the same year that 14-year-old Emmett Till was lynched in Mississippi. The poem’s revelation is a simple one. For black Americans, coming of age means coming to terms with the constant threat of extreme racial violence.
Poetry’s success often relies upon showing people aspects of the world which they might otherwise have ignored, repressed or simply missed.
Some poetry experiments with form itself to produce this revelatory effect. Estate Fragments (2014) is a long poem written by Gavin Goodwin, exploring the Bettws council estate in Newport. It juxtaposes quotations from academic writing alongside interviews with residents – a practice referred to as “found poetry”.
Goodwin attempts to consider the effect that seemingly abstract political decision-making and discussions have on a particular place and community. Take this stanza:
Increased inequality
ups the stakes
‘People that were younger than you
were more dangerous.’
The first two lines quote Common Culture by Paul Willis (1990), a sociological study in the cultures of young people. The latter are from an interview with a resident of the Bettws estate. Together, they tell a story: national economic inequality causes people in a working-class community to fear each other.
Looking closer and looking deeper
More conventional lyric poetry can still reveal sociopolitical realities. Canadian Métis Nation writer katherena vermette’s collection North End Love Songs (2012) explores the North End in Winnipeg, Canada. In a CBC interview, vermette discussed how the local community are:
The people that get picked on [and] blamed … but what I’m trying to do in my work is to go into looking closer and looking deeper … and seeing that they’re not what they seem.
Misinformation and polarisation cause social tension, as particular groups are generalised and blamed. Vermette’s poem indians explicitly explores the devastation caused by preconceptions of peoples and places.
The poem recalls vermette’s brother going missing, before being found in the Red River, a powerful body of water that moves through Winnipeg. It focuses on the apathy of Winnipeg’s police service, who tell the family that there is “no sense looking”, as the man will return when “he gets bored/or broke”. The authorities come to this conclusion not through investigation, but by reducing the speaker’s brother to racist stereotypes.
This is then contrasted with what the family “finds out”. Not only has the brother drowned, but the “land floods/with dead indians”. The speaker discovers the fate of her brother is also the fate of many other Métis people in Winnipeg. This personal experience of loss comes to speak for many other loses:
indians get drunk
don’t we know it?
do stupid things
like being young
like going home alone
like walking across a frozen river
not quite frozen
Vermette links grief to struggles against systematic apathy and oppression. The poem’s sense of politics, people and place are a central part of its poetics.
Such explicitness means the poem meaningfully connects to important political issues – drawing attention to the startlingly high number of missing people found and suspected to be in the Red River. As such, it can also link to important grassroots initiatives like Drag the Red, which aims to “find answers about missing loved ones” which might lie in the river.
While North End Love Songs was published two years before Drag the Red’s formation, the poem and initiative are clearly formed by the same kind of traumatic, sociopolitical events.
Newsfeeds increasingly silo us into comfortable ways of thinking and perceiving. Forty years on, Lorde’s declaration that poetry “is not a luxury” takes on a whole new meaning. Now, it might be a political necessity.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Alex Hubbard is formerly affiliated with the Labour Party, and Aber Food Surplus, a community hub.
Source: The Conversation – UK – By Anna Matveeva, Visiting Senior Research Fellow, King’s Russia Institute, King’s College London
At a time when Vladimir Putin needs friends in his neighbourhood, he appears instead to be losing them in the South Caucasus. After two centuries of Russian involvement in the region, balancing the historical rivalry and at times acting as mediator between Armenia and Azerbaijan, there is growing speculation that the two countries are preparing a major reset in relations.
When Armenia’s prime minister, Nikol Pashinyan, met the Azerbaijani president, Ilham Aliyev, in Abu Dhabi on July 10, they reportedly came close to agreeing a peace treaty. The big question is whether, if these two countries can iron out mistrust and violence born of the territorial conflict, there will still be a role for Russia in the South Caucasus.
To understand the complex geopolitics of the region, you need to go back to the early 19th century, when Azerbaijan and what is now the Republic of Armenia) were ceded to Russia following the Russo-Persian wars. After the Russian revolution, the two countries achieved brief independence between 1918 and 1920 (though not in their present borders) before being incorporated into the Soviet Union.
During the Soviet era, the union republics of Armenia and Azerbaijan both felt that Moscow favoured the other. Armenia was unhappy that the Soviet leadership allocated Nagorno-Karabakh, a majority-Armenian exclave surrounded by Azeri-populated lands, to Azerbaijan. Azerbaijan was dissatisfied that its borders denied it a land connection to its population in Nakhchivan, an exclave of ethnic Azeris that could only be reached via southern Armenia.
In the final years of the Soviet Union, as Armenian nationalism began to assert itself during the period of perestroika (restructuring), Nagorno-Karabakh’s legislature passed a law declaring its intention to join Armenia. This move eventually led to armed clashes in the region.
The first Karabakh war, which raged between 1988 and 1994, began before the Soviet break-up but continued after the two countries gained their independence. In 1994, after more than 30,000 casualties, Russia brokered a ceasefire. The settlement favoured Armenia, leaving it in control of Nagorno-Karabakh and another six surrounding Azerbaijani districts.
Things began to change when Putin took power in Russia in 2000. Russia’s relations with Azerbaijan improved, partly due to his personal rapport with the then-president, Heydar Aliyev, and his son Ilham, who would succeed him in 2003. After 9/11, when combating international terrorism became a global priority, Azerbaijan put measures in place to prevent transfer of fighters and weapons through its territory to the war in Chechnya, which further improved relations with Moscow.
At this stage, Azerbaijan was pursuing what it described as a “multi-vector” foreign policy. This allowed it to develop ties with a variety of countries, including the US, Russia and others to whom it sold oil. While remaining in the Commonwealth of Independent States, it did not sign up to the Russia-led Collective Security Treaty Organisation (CSTO).
Nagorno-Karabakh
Armenia, by contrast, was a fully participating member of the CSTO. Having signed an Eternal Friendship Treaty with Russia in 1997, this was a clear strategic choice for Armenia – partly motivated by historical ties.
Russia had traditionally been seen as a defender of Christianity in the days of the Ottomon empire. Many people had fled massacres in Western Armenia (modern-day Turkey) in 1915 to come under the protection of the Russian Tsar. But Armenia also saw Moscow as a vital security guarantor against an increasingly militarised Azerbaijan, which was determined to recover control of Nagorno-Karabakh and other areas occupied by Armenia.
Map showing the concept of the ‘Zanzegur corridor’, which would cut across southernmost Armenia to connect Azerbaijan with Nakhchivan. Mapeh/Wikimedia Commons, CC BY-NC
Indeed, it was Nagorno-Karabakh which really soured relations between Armenia and Moscow. In 2020, when – aided by Turkey – Azerbaijan launched its offensive to retake the territory, Russia failed to come to the aid of its CSTO ally. This was expected, given that relations had begun to deteriorate in 2018 when Pashinyan came to power in Armenia.
In hindsight, most commentators believe Russia had become tired of Armenia’s intransigence over the plan, agreed in Madrid in 2007, for it to cede back the six districts surrounding Nagorno-Karabakh to Azerbaijan.
Instead, Moscow brokered a ceasefire agreement and deployed 2,000 peacekeepers along the Lachin corridor, a strip of land connecting Armenia and Nagorno-Karabakh. But these troops also failed to intervene when an Azeri offensive retook the whole of Nagorno-Karabakh in September 2023, forcing the population of about 100,000 ethnic Armenians to flee.
Relations between Russia and Azerbaijan, meanwhile, have gone downhill rapidly. In December 2024, an Azeri civilian airliner was shot down in Russian airspace. Putin apologised, but Azerbaijan insisted on Moscow disclosing the results of the investigation and paying compensation to the victims.
Things got worse at the end of June, when Russian authorities arrested a group of ethnic Azerbaijanis as part of a decades-old murder case. Two of the men died while being detained. Azerbaijan retaliated by raiding the Baku offices of Russia’s Sputnik news agency and detaining the staff as well as a group of Russian IT workers. When they appeared in court, some of the men appeared to have been beaten in custody.
Azerbaijan also denounced Russia in state media and Russia House, the state-funded Russian cultural agency in Baku, was closed down, with several cultural events cancelled. Security agencies began to enforce documentation checks on all Russian nationals in the country.
At the same time, Azerbaijan and Armenia were already talking about concluding a peace treaty independently, without intermediaries. All this has prompted speculation of a serious loss of influence in the region for Moscow.
However, a complete shutout of Russia in the South Caucasus is unlikely. Both Armenia and Azerbaijan depend on remittance income from their nationals in Russia. Both countries also remain close trading partners with Russia. While Armenia suspended its membership in CSTO, it has not quit the organisation altogether.
Far more likely is that the two countries, mindful of the growing influence of Turkey in the region and the shifts created by Donald Trump in world affairs, are manoeuvring while weighing their options. Geography matters, as Georgia’s example demonstrates – efforts to cut ties with Russia by its former president, Mikheil Saakashvili, have been partially reversed by the current government, which increasingly leans towards Moscow.
In the cases of Armenia and Azerbaijan, economic ties, transport links and human connections still favour a relationship with Russia. So, a temporary breakdown in political relations can be mended – if all three leaders demonstrate enough statesmanship to sail through the troubled waters.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Anna Matveeva does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Cuba doesn’t have any beggars, according to the country’s minister of labour, Marta Elena Feitó Cabrera. In a speech to the national assembly on July 15, she denied the existence of destitution in the communist country, claiming the problem was actually people “disguised as beggars”.
Her words were greeted by public outcry on social media. They also prompted a swift rebuke from her peers and the president, Miguel Díaz-Canel, who said leadership could not “act with condescension”. The next day, the Cuban government published an official note saying Feitó Cabrera had resigned.
The political vulnerability of the Cuban government explains the urgent need to respond to missteps such as Feitó Cabrera’s. The country is enduring an acute economic crisis, which has seen living standards plummet and over 1 million Cubans leave the country since 2020.
Cubans are leaving en masse:
A severe economic crisis in Cuba has prompted a mass exodus from the island. Oficina Nacional de Estadísticas e Información
The recession has severely strained the system of social protection that the government points to as one of its main achievements since taking power more than 60 years ago. Despite food subsidies and the efforts of welfare services, a growing number of people are now going hungry.
Public confidence in the government has been severely weakened as a result, particularly among young Cubans. The risk of escalating popular protest is magnified by the proliferation of social media channels, emanating from inside and outside the country.
These channels air the many complaints about daily frustrations in Cuba and highlight any failings or signs of hypocrisy on the part of officials. So when Feitó Cabrera’s speech went viral, it was met with inevitable public outrage.
Díaz-Canel’s reaction can be seen as urgent damage limitation. But it is also consistent with his broader approach to managing the crisis facing his country. He has worked tirelessly to try and defuse anger through engagement, touring Cuba for local meetings to search for solutions.
In his comments after Feitó Cabrera’s speech, he insisted that officials should acknowledge the scale of hardship being suffered, and “help, support and show solidarity” with the disadvantaged and most vulnerable.
This need to reach out was all the more important given the grim tone of the national assembly meeting where Feitó Cabrera made her remarks. Ministers appeared one after the other to present dismal reports on the state of almost all sectors of the Cuban economy.
The electricity system remains plagued by breakdowns caused by chronic underinvestment as well as difficulties in obtaining fuel and spare parts. The resulting daily power outages ensure that the sense of crisis is ever-present and frustrate all efforts to boost production.
Doubting official data
While full official national income data for 2024 has not yet been released, Cuba’s economy ministry estimates that real national income contracted by 1.1% in 2024. This leaves it more than 10% below its pre-pandemic level, and 2025 is not expected to show much improvement.
The decline in real disposable income for Cuban households since 2021 has, in reality, been far greater. The official inflation rate indicates that consumer prices have risen fourfold over the past five years. At this rate, living costs would have increased broadly in line with salaries.
Consumer prices have risen fourfold since 2020:
Official inflation data for Cuba. The spike in early 2021 was the result of a monetary reform, which involved a big jump in wages in December 2020 followed by a currency reform in January 2021. Oficina Nacional de Estadísticas e Información
But official figures systematically understate the actual increase in prices faced by Cuban households, due to the weightings used. In 2021, for example, research estimated the inflation rate to be between 174% and 700% – well above the government’s estimate (77.3%).
The rising market prices have put many essential goods beyond the reach of most people who depend on state incomes. This has forced many households to depend on remittances or the informal economy to survive.
Thanks to tight fiscal restraint, the official annual rate of inflation eased to 15% in June. But the wide gap between the increase in the actual cost of living and official inflation index continues to compound distrust of the government and the perception that the country’s leaders are out of touch.
A lack of transparency and long delays in the publication of economic data, together with restrictions on the scope for private enterprise, are widely attributed to the government’s incompetence and reluctance to enact liberalising reforms.
Recovery blocked by US sanctions
For these reasons, the government’s insistence that US sanctions are to blame for limiting the possibilities for economic recovery is increasingly regarded with scepticism. However, the constraint on economic growth imposed by US measures is real and severe.
It is also the deliberate aim of US policy. The unilateral sanctions not only block trade, as well as financial and international travel between the US and Cuba. They also severely hamper all kinds of transactions between Cuba and the rest of the world.
Every branch of the Cuban economy has been affected, including the health service, social safety nets, agriculture and industry. And the lack of hard currency has, in turn, limited the scope for the investments and reforms needed for economic recovery.
The easing inflation rate, together with some new investments in renewable energy, an improved fiscal balance and a recent small increase in pensions, may signal that the end of the economic downturn may be approaching. But neither the government nor the population have any confidence that the crisis will come to an end this year.
No one is expecting US sanctions to be lifted while Donald Trump is president. Before Trump first stood for the presidency he hadn’t given Cuba his attention, but as president he has aligned himself firmly with hardliners.
In his first term, Trump reversed the opening with Cuba initiated by Barack Obama. And his current secretary of state, Marco Rubio, is one of the architects and leading proponents of economic sanctions against Cuba. Trade and investment will thus remain depressed, while shortages, power cuts, a lack of transport and crumbling public services will persist.
But by demanding the resignation of the minister of labour, perhaps Díaz-Canel hopes to demonstrate that his government understands what that the economic asphyxiation means for a majority of Cubans struggling to survive.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Emily Morris does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
The retirement age keeps creeping up. In the UK, the state pension is currently paid to people at 66, but that’s set to rise to 67 in the next couple of years, and a move to 68 might come sooner than previously planned after the government launched a review.
Gradually increasing the working lifespan is never going to be popular. But one way of making this policy more palatable could be to give people early access to some of the free time that retirement promises.
After all, sometimes that promise fails to deliver, because many people die before they reach retirement age.
Globally, about 27% of men and 18% women die before the age of 65 (although this proportion also includes deaths before working age). In wealthy countries, the number of people who die prematurely is lower than the global average, but still significant. In the EU, 16% of men and 8% of women die before 65.
For these people, the promise of free time and leisure in old age never materialises. There will also be many whose physical and mental health will have deteriorated by the time they retire, so that they are less capable of enjoying their free time.
So perhaps slogging away until retirement is not an ideal arrangement.
But what if you could transfer some of the time off that retirement promises to an earlier stage of your life, when everything is a rush, crammed with the demands of work and domestic responsibilities?
Luckily, the stark contrast between a time-poor middle age and a time-rich old age is not unavoidable. Governments can choose different approaches that directly affect how free time is distributed across our life stages.
Japan, for example, is a country which has opted to focus on delaying leisure time, and encourages workers to postpone that enjoyment of free time until old age. It does this in part by rewarding workers with wage increases – known as “seniority-based pay” – if they don’t take career breaks.
Japanese employment law also permits companies to force employees to retire at the age 60. As a result, on average, Japanese workers work 1,680 hours per year and retire at 63.
In the Netherlands by contrast, people work less (1,433 hours per year) and retire later – at 67. Labour laws make it easier for employees to decrease their hours, by going part time, for example.
Discrimination between workers based on work hours is prohibited, so that those who opt for part-time work are guaranteed equal treatment with regard to wages and other benefits. But the high legal age of retirement discourages Dutch workers from early retirement.
So how should we assess these different approaches?
Time on your side?
One way to look at retirement is that it compensates us for our previous hard work. The prospect of compensation might lead us to adopt a relaxed attitude toward long work hours. Once we’ve stopped work, we’ll be rewarded with a large chunk of leisure.
But for those who don’t make it to retirement, this promise of a life of leisure turns out to be a cruel joke. Early deaths are also more prominent among those who have already suffered from poverty and other disadvantages.
The same is true for ill health. The disadvantaged are much more likely to suffer from a variety of conditions that prevent them from being able to fully enjoy retirement.
Another risk for those who are healthy when they retire is that relatives or friends may have died. This reduces the value of the retirees’ free time because the loved ones they hoped to share that time with are no longer around.
So perhaps some of that free time could be better used when workers are younger. Raising a family, for example, is extremely time consuming, and there can’t be many parents of young children who don’t wish for a few extra hours a week to call their own.
Even devoting time to hobbies when we’re younger might be considered more efficient than waiting until we have retired. After all, if you learn a new language or how to paint when you’re in your 40s, you may have much more time to enjoy your new skill over the ensuing decades.
My research suggests that for all these reasons, the state should help people take some of their retirement early.
None of us knows how long we will live, or how healthy we will be in the future. Faced with this uncertainty, it makes sense not to gamble with our opportunities for free time and leave it until it may be too late.
Even those who enjoy their work have strong reasons not to postpone a large proportion of their time off, and governments should help us access more of it while we’re younger.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Malte Jauch does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Green tea and red wine may seem like simple dietary choices – but beneath the surface, they harbour compounds with remarkable medical potential. Scientists are uncovering how these everyday drinks might support cancer treatment, not by replacing conventional therapies like chemotherapy or radiotherapy, but by enhancing their effectiveness and reducing their side-effects.
The humble cup of green tea, first enjoyed in first-century China, has long been valued for its cultural significance and traditional health benefits. Tea has historically been used to combat ageing, protect the brain and heart, and aid weight loss. Today, researchers are uncovering a more profound capability – its potential to fight cancer.
The key lies in epigallocatechin gallate (EGCG), a potent antioxidant found in this kind of tea. Antioxidants are protective molecules that help shield cells from damage caused by free radicals and environmental stress, but EGCG appears to do much more.
Cancer cells are notoriously disruptive, hijacking the body’s normal energy-systems to fuel their rapid growth. EGCG targets this very process, disrupting how cancer cells generate energy, and attacking the proteins that help tumours grow and divide. By targeting these proteins, it prevents cancer from multiplying, ultimately leading to cell death.
Even more promising is EGCG’s ability to enhance conventional treatments. Early studies suggest it could make cancer cells more vulnerable to chemotherapy and radiation therapy, potentially reducing the need for high doses and their severe side-effects.
Red wine, too, offers compelling potential, thanks to a substance called resveratrol. This compound is found in red grapes, blueberries and peanuts, and has been shown to support the heart, liver and brain. Interestingly, resveratrol works through mechanisms distinct from EGCG.
Rather than targeting cancer cells directly, resveratrol focuses on the tumour’s environment. Cancer cells cleverly surround themselves with blood vessels and supportive tissue, creating a protective fortress that aids growth and spread. Resveratrol disrupts this structure, making tumours vulnerable to conventional treatments.
The compound also enhances the immune system’s ability to recognise and attack cancer cells more effectively. Perhaps most significantly, resveratrol prevents tumours from forming new blood vessels – the lifelines they need to obtain nutrients for growth. Without this blood supply, tumours become starved and eventually die.
The cancer-fighting compound resveratrol can be found in red wine. It is especially high in tannat wines. Nikolaj Sribyanik/Shutterstock.com
Beyond the glass
The potential of natural cancer-fighting compounds extends far beyond our favourite beverages. Apigenin, found in parsley, can slow tumour growth, while turmeric contains curcumin, which disrupts cancer-cell survival. And emodin, found in aloe vera and rhubarb, reduces inflammation and inhibits cancer growth.
However, scientists face a significant challenge: many of these natural substances are poorly absorbed by the body. Research in this area is currently focused on developing enhanced delivery systems, such as wrapping the compounds in tiny lipids called nanoparticles. This approach protects the substances and increases their effectiveness against tumours.
The absorption of natural substances are further improved by mixing compounds with each other such as piperine with curcumin. Piperine is found in black pepper and helps curcumin based nanoparticles to have better bioavailabilty in cancer therapy.
While the research remains in its early stages, the possibility that everyday foods and drinks could one day support cancer treatment represents a fascinating frontier in medical science.
So the next time you reach for a cup of green tea or a glass of red wine, consider this: you may be doing more than relaxing – you could be reinforcing your body’s natural defences against cancer.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Ahmed Elbediwy does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and have disclosed no relevant affiliations beyond their academic appointment.
Nadine Wehida does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
I have spent the past two years examining the living conditions in informal refugee camps along the northern coast of France as part of an ongoing research project on borders. These sites are where people gather before attempting to cross the Channel to the UK.
The UK government recently announced a returns agreement to discourage people from making the crossing and economic sanctions
against people smugglers, following an increase in funding for border control and a decision to use counter-terrorism tactics in an effort to “smash the gangs”.
But from what I have observed, such policies appear to do little to stop people from making the journey. Quite the opposite – the more police crack down, the more the smuggling networks take risks to get around difficulties.
My fieldwork has been primarily conducted through volunteer work with Salam, a grassroots organisation that provides hot meals and clothing to the main informal camps in Calais and Dunkirk. I have also collaborated with other groups such as Alors on Aide and Opal Exil.
In the past few years, smuggling networks have adjusted their tactics to evade police. While smugglers used to inflate boats on the beaches between Calais and Dunkirk, they are now mostly using “taxi boats”. These leave further north or south on the coast, as far as Le Touquet. They then pick up groups of refugees waiting in the water along the coast, avoiding police intervention.
A microcamp in Ecault Forest. Sophie Watt
In response, and in order to intensify the crossings, “microcamps” have emerged – smaller temporary settlements closer to the beach, along the coast between Hardelot and Calais. These microcamps act as connecting points between the larger camps and the coastal departure locations where taxi boats pick them up. They allow for people to make several attempts at crossing without having to return to the large camps, where living conditions are more difficult.
The larger camps (such as Loon Plage and Calais) are the epicentre of the smuggling operations. The camps are evicted at least once a week (every 24 hours in Calais) due to France’s official “zero fixation point” policy. This policy, which bars people from forming long-term settlements, was implemented after the dismantling of the Calais “Jungle” refugee camp in October 2016.
Camp conditions
Police efforts to uphold the zero fixation point policy entail frequent evacuations, restrictions of humanitarian aid and physical site disruption. At Loon Plage, I saw that the sole access to water is a livestock trough.
Official guidance from the UN’s refugee agency states that, irrespective of the informality of these camps, their residents should have access to water, sanitation and shelter.
Access to water is limited to troughs. Sophie Watt
The non-profit watchdog group Human Rights Observers has documented instances of police violence and seizures of people’s belongings and tents at the camps.
In addition to regular evictions of the larger camps, the microcamps have recently seen more brutal police action. There have been reports of police using teargas, puncturing life jackets and tents, contributing to untenable living conditions. Violence and shootings between smuggling groups have also been reported in Loon Plage camp.
While working with Alors On Aide and photographer Laurent Prum we met around 50 people, including seven children (ages one-17), in a microcamp on the edge of the Ecault forest near Boulogne-sur-Mer. We immediately noted a tension between the group and the gendarmes who were standing watch.
Most of this group had spent a few years in Germany before being refused asylum. They told me they felt they had been forced to come back to France, because of the deportation measures currently being implemented by the German government.
A few confided that this was their fifth and final try at crossing the Channel. This is a new tactic the smuggling organisations use to make more money more rapidly: while refugees used to be able to try as many times as they needed, they now have to pay again after five failed attempts.
The previous day, this group told us they had been chased out of another part of the forest. There, we had found several empty canisters of tear gas – consistent with reports that French police have deployed tear gas in operations against informal camps.
This group had wanted to stay there because they could use a dilapidated shed to shelter themselves and their children from the rain. Eventually, the gendarmes evicted them, forcing them to spend the night in the rain – the field in question was privately owned. Following the eviction, we witnessed that the landowner had covered the area with manure to stop them returning.
A young Sudanese man showed us videos of the altercation. The exchange, during which five people were arrested, was violent. The children were terrified and the video showed the gendarmes using teargas against the group. A Palestinian mother was arrested and taken into custody, forced to leave her two young daughters. Her husband asked me: “Why did they arrest her when they could see she had two children with her?”
Alors on Aide mobilised several of its members to bring clothes, blankets and food for the group, and got the Palestinian woman released from custody, as she had not been charged with any offence.
While living conditions in camps and the capacity of the French asylum system make staying in France difficult, police are also taking firmer action against boats attempting the crossing.
As part of a coastal patrol (helping refugees after a failed crossing attempt), we arrived on the beach in Équihen at around 7am on July 4 to find that French police had just punctured a boat in the water.
The UK government praised French police for this action, performed in front of international media. The UK and France have also discussed allowing coastguards to intercept taxi boats up to 300 metres off the coast.
This would be a marked change from current regulations, which prohibit French police from intervening offshore except when responding to passengers in distress. Even the border police have doubts about the legal basis for this measure and its practical implications at sea, particularly given the heightened risk of accident.
Trapped between hounding by police on the beaches and constant evacuations from the informal settlements, the refugees have no choice but to try to cross the Channel at any cost. A record number of 89 refugees died at the Franco-British border in 2024. Thirteen deaths at sea have already been recorded in 2025.
In my view, the recently announced French-British measures to intensify policing and border enforcement are unlikely to deter people from attempting dangerous crossings. Instead, they will create an incentive for more dangerous tactics by smugglers, putting more lives at risk and violating human rights. Any agreement to return asylum seekers, restrict their access to asylum or force people back across borders will exacerbate the dangers already experienced by those seeking refuge.
Sophie Watt receives funding from the University of Sheffield and the British Academy / Leverhulme Small Research Grants.
When we look at how people vote in elections and why they choose certain parties, analysis often focuses on age, education, location or socioeconomic status. Less discussed in Britain is religion. But close to two-thirds of its adults are still religious – expressing either a religious identity, holding religious beliefs, or taking part in religious activities.
For the one-in-three adults in Britain who are Christian, this identity remains an important influence on their political behaviour. New polling, published here for the first time, shows how Reform UK is disrupting our previous understanding of how Christians vote in British elections.
Want more politics coverage from academic experts? Every week, we bring you informed analysis of developments in government and fact check the claims being made.
The relationship between Britain’s Christian communities and the major political parties goes back centuries. The Conservative party has been very close to English Anglicanism since its emergence in the mid-19th century. Catholics and free-church Protestants (such as Baptists and Methodists) have tended towards the Labour and Liberal/Liberal Democrat parties. Even as Britain has become more secular, these relationships have persisted.
Anglicans, for example, have tended to vote Conservative even when the party was in dire straits. In the 2024 election, 39% of Anglicans voted Tory even as the party’s national vote share fell to 24%.
Since the 1980s and particularly in elections since 2015, however, we have started to see changes to the Christian vote. The traditional Catholic attachment to Labour has deteriorated, as has Labour’s appeal to other Christian communities such as Baptists, Methodists and Presbyterians.
Instead, driven by the rising salience of social values (attitudes towards immigration, social change and national identity) as a determinant of political support, the socially conservative leanings of some Christians of all stripes has led to increased support for the Conservatives. And those who traditionally did so – the Anglicans – have become even more supportive. The result has been a steady coalescing of the Christian vote behind the Conservatives.
But now, new polling by YouGov (on June 23-24 2025) for the University of Exeter reveals that this realignment is being disrupted by the growing popularity of Reform UK.
Instead of asking who people would vote for tomorrow, a nationally representative sample of 2,284 adults was asked how likely they were to ever vote for each major party, on a scale from zero (very unlikely) to ten (very likely).
While not the same as a direct question about how someone would vote in an election, the likelihood question provides a much richer measure of the strength of their support for all of the major parties.
Stuart Fox, data by YouGov for the University of Exeter
Among Anglicans, Labour remains deeply unpopular: over half gave the party a 0. In contrast, the Conservatives still enjoy strong support among Anglicans, with 35% giving them a vote likelihood of seven or higher – the kind of support associated with voting for the party in an election.
Reform, however, has caught up. Despite only 15% of Anglicans voting Reform in 2024, 38% now rate their likelihood of voting for the party as high. That’s the same as the proportion who are strongly opposed to Reform – showing that while the party polarises Anglicans more than the Conservatives, Reform could win as much Anglican support as the Tories in an election.
Catholics show a similar trend. Labour’s traditional support is eroding: 40% of Catholics said they had zero likelihood of voting Labour, while 29% are strong supporters. As with Conservatives for the Anglican vote, Reform is almost level-pegging with Labour for the Catholic vote at 28%. It has even supplanted the Conservatives, of whom 22% of Catholics are strong supporters.
It is not yet clear why this is happening. The distinction of Christian (and non-Christian) voting patterns is not an artefact of age – there are manystudies that prove this is the case.
It may be that Reform’s stances on issues such as immigration resonate with Christians’ concerns to the extent that they are willing to set aside their historic party loyalties. Or it may be that Christians are as prone as other British voters to turn to Reform out of frustration with the performances of Labour and the Conservatives in office.
Swing voters and party competition
This data also shows the extent to which voters’ support for parties overlaps or is exclusive. In other words, which voters have a high vote likelihood for only one party (and so are likely committed to backing that party in an election), which do not have such high likelihoods for any party (and so will probably not vote at all), and which have similarly high likelihoods for more than one party (effectively swing voters, persuadable one way or the other).
Among the religiously unaffiliated, 29% aren’t strong supporters of any party. For Catholics, it’s 26%. Anglicans are more politically anchored, however, with only 20% in this category.
While traditionally, we would have expected this to reflect Anglicans’ greater tendency to support the Tories, only 17% of Anglicans are strong supporters of only that party, compared with 21% who are firmly behind Reform. These aren’t swing voters; they’ve switched sides.
A further 12% of Anglicans have high vote likelihoods for both the Tories and Reform. These are swing voters that the two parties could realistically expect to win over.
Stuart Fox, data by YouGov for the University of Exeter
Catholics are even more fragmented. Only 13% are strong supporters of Labour alone, along with 12% and 17% who are strong supporters of the Conservatives and Reform alone, respectively.
Few Catholics are torn between Labour and the other parties, but 5% are swing voters between the Conservatives and Reform: the Tories’ gradual winning over of Catholics over the last 50 years is also being challenged by the appeal of Reform.
The party has provided a socially conservative alternative to the Conservatives, with the result that the Christian vote has become more fragmented. The Tories are no longer the main beneficiaries of Labour’s loss of its traditional Catholic vote.
In addition, Reform is as popular as the Conservatives among Anglicans, and as popular as Labour among Catholics. This suggests it is appealing across the traditional denominational divide more successfully than either of the major parties.
If there is to be a single party that attracts the bulk of Britain’s Christian support, at this point it is far more likely to be Reform than anyone else.
This article was based on analysis by Dr Stuart Fox (University of Exeter), Dr Ekaterina Kolpinskaya (University of Exeter), Dr Steven Pickering (University of Amsterdam) and Prof Dan Stevens (University of Exeter), connected to the research project Investigating the individual and contextual role of religion in British electoral politics, funded by the Economic and Social Research Council. Stuart Fox also receives funding from the British Academy.
“We’re actually facing, in many parts of our country, nothing short of societal collapse.” This was the dire warning from Reform UK leader Nigel Farage, in setting out his party’s goal of halving crime.
In an op-ed in the Daily Mail and a press conference, Farage framed Britain as a nation in crisis from rising crime and lawlessness. But, he said, Reform had the solution: mass deportation of foreign offenders, the construction of prefabricated “Nightingale” prisons, and a wholesale crackdown on offending.
He insisted that British streets were out of control (although recent rises in crime come mainly from online fraud and shoplifting, according to the latest data), pledged to simultaneously increase prison sentences and reduce overcrowding, and vowed to restore order with a “higher and physically tougher standard of police officer”.
Speaking after a weekend of violent anti-immigration protests in Epping, Farage also tied Britain’s supposed lawlessness to migration: “Many break the law just by entering the UK, then commit further crimes once here – disrespecting our laws, culture and civility. The only acceptable response is deportation.”
Invoking crime as a threat, and the politician as its solution, is a tried-and-tested political manoeuvre. We’ve seen it deployed from both left and right, in many parts of the world, for decades. Stuart Hall and colleagues famously examined this phenomenon in the 1970s in their seminal book Policing the Crisis.
Our own analysis suggests that the accuracy of crime statistics often matters less than how politicians frame public anxieties – through media, public rhetoric and policy initiatives. In short: the public often responds to emotion as much as evidence.
One tension in England and Wales is that there are two major sources of crime data. The first – on which Farage leans heavily – is police-recorded crime. But, as is widely understood, that data provides only a partial picture of the true extent of crime. Many people, especially those from marginalised or vulnerable groups, choose not to report their experiences of crime.
Moreover, the consistency and accuracy with which police forces record these offences has been questioned over time. Indeed, police-recorded crime statistics are not designated as official national statistics.
The other (and more robust) source is the Crime Survey for England and Wales (CSEW), which asks a representative sample of the public about their experiences of crime over the past 12 months. Notably, it includes those incidents that were not reported to the police.
Running since the early 1980s, the CSEW has demonstrated long-term declines in incidents of theft, criminal damage and violence (with or without injury) since the mid-to-late 1990s. Curiously, Farage told reporters that the CSEW was “based on completely false data”, without providing any evidence.
The Office for National Statistics (ONS), and most criminologists, regard the CSEW as the more accurate metric of long-term crime trends. (The Conversation asked the CSEW to comment but hadn’t received a response when this article was published.)
The political weight of crime
Crime has electoral value. It allows parties and political campaigners to project strength, decisiveness and control. Farage’s rhetoric is designed to provoke urgency and anxiety. It’s a well-worn script. Margaret Thatcher’s government leveraged fears of law and order. New Labour made “anti-social behaviour” a central point of focus at a time when crime was, in fact, falling.
In research conducted with colleagues, we examined how people’s fears about specific crimes are shaped not just by actual crime rates, or by the person’s age, gender or ethnicity, but also by the political context in which they grew up.
Using data from the CSEW and a method called age-period-cohort analysis, we explored how different “political generations” developed and retained distinct concerns about crime.
We found clear patterns. Those who grew up during the James Callaghan era in the mid-to-late 1970s – when politicians repeatedly warned of “muggings” – were more likely to report anxieties about street robbery over time.
Thatcher’s generation, who came of age during a sharp rise in property crime, were more likely than other groups to express long-term fears about burglary. And those who grew up under New Labour – during the height of the “anti-social behaviour” agenda – reported persistent concerns about neighbourhood disorder, even as recorded incidents declined.
In other words, the political rhetoric people are exposed to during their formative years leaves a lasting impression on their relationship to crime. Debates about crime become embedded in personal and generational memory.
Crime is real and victims suffer. But distorting its nature and prevalence can erode public trust in the institutions tasked with protecting us. It can foster punitive and ineffective policy responses. And it can leave whole communities feeling targeted, criminalised or unsafe, based on selective and often sensational narratives.
We absolutely need to talk about crime. But we also need to talk about how we talk about crime. Who frames the debate, which statistics are used, who and how many are left out of the official records, whose fears are being amplified, and who is looking to exploit crime?
Emily Gray has received funding from the Economic and Social Research Council.
Stephen Farrall has received funding from the Economic and Social Research Council.
I’m not sure if it was the effect of the atomic bomb, but I have always had a weak body, and when I was born, the doctor said I wouldn’t last more than three days.
These are the words of Kazumi Kuwahara, a third-generation hibakusha – a survivor of the atomic bombing of Hiroshima and Nagasaki in Japan 80 years ago.
Kuwahara, who still lives in Hiroshima, was in London on May 6 this year to give a speech at a Victory Over Japan Day conference organised and hosted by the University of Westminster. Now 29, she told the conference that she felt she had been “fighting illness” throughout her 20s. When she was 25, she needed abdominal surgery to remove a tumour which post-surgery tests showed was benign.
When she found out about the operation, her grandmother, Emiko Yamanaka – now aged 91 and a direct survivor of the atomic bombing of Hiroshima – told her: “I’m sorry, it’s my fault.” Kuwahara explained:
Ever since I was young, whenever I became seriously ill, my grandmother would repeatedly say: ‘I’m sorry.’ The atomic bombing didn’t end on that day and the survivors – we hibakusha – continue to live within its shadow.
Kazumi Kuwahara with her grandmother, Emiko Yamanaka, outside Hiroshima Peace Dome in 2025. Kazumi Kuwahara, CC BY-NC-ND
Kuwahara came to stay with me ten years ago during a study abroad break after I had interviewed her grandmother for my doctoral research. When I’d made a film about Yamanaka in 2012, I immediately noticed her reluctance to share her harrowing experience. But she then invited me to interview her in Hiroshima – the first of ten trips I made there for research which would become an interview archive.
I wanted to research hibakusha like Kuwahara and her grandmother as they continue to confront the physical, social and psychological effects of the atomic bombs dropped on August 6 and August 9 1945, on Hiroshima and Nagasaki respectively.
The 16-kiloton bomb dropped on Hiroshima at 8.15am by a US B-29 bomber was codenamed “Little Boy” by the Americans. It exploded about 600 metres above the Shima Hospital in the downtown area of Nakajima – a mix of residential, commercial, sacred and military sites. The bomb emitted a radioactive flash as well as a sonic boom. A gigantic fireball formed (about 3,000–4,000°C), as well as an atomic mushroom cloud which climbed up to 16km in the air.
In Japan in the immediate aftermath of the bombing, people couldn’t even utter the phrase “atomic bomb” due to censorship rules initially enforced by the Japanese military authorities, up until the day of surrender on August 15. The censorship was reinstated and expanded by the US during its occupation of the Japanese islands from September 2 1945.
The Insights section is committed to high-quality longform journalism. Our editors work with academics from many different backgrounds who are tackling a wide range of societal and scientific challenges.
For decades, the hibakusha have faced discrimination and difficulty in obtaining work and finding marriage partners due to a complex combination of suppression, stigma, ignorance and fear around the dropping of the atomic bombs and their aftereffects.
Wartime propaganda in Imperial Japan precluded free speech while also imposing bans on luxury goods, western language and customs (including clothes) and public displays of emotion.
However, the US occupation – which lasted until the San Francisco treaty was signed on April 28 1952 – went further, establishing an extensive Civil Censorship Department (the CCD) which monitored not only all newspapers, magazines, pamphlets, books, films and plays but also radio broadcasts, personal mail, as well as telephone and telegraph communications. Little wonder the scars of the bomb remained untreated, for generations.
Emiko Yamanaka’s story
Yamanaka was 11 years old when she was exposed to the atomic bombing, just 1.4km from ground zero.
Emiko Yamanaka (far left) with her four brothers and parents during wartime before the atomic bombing in 1945. Emiko Yamanaka
She told me about her experiences of surviving on the bank of the River Ota, which divides into seven rivers in the estuary of Hiroshima. Yamanaka was the oldest of five siblings in 1945. Although the family had been evacuated to an island near Kure 25km away, she returned to their home on the outskirts of the city with her mother and nine-year-old brother early on the morning of August 6, so she could attend an appointment with an eye-doctor for a case of conjunctivitis.
Making her way into the city by herself, the tram she was travelling on needed to stop due to an air-raid warning. It was a “light” warning as just two B-29s had been spotted approaching the mainland (a third photography plane was not yet visible on the horizon), so Yamanaka needed to continue her journey on foot. She recalled:
When I got to Sumiyoshi shrine, the strap of one of my wooden geta [Japanese clogs] had snapped off. I tried to fix it with a torn piece of my handkerchief in the shade of a nearby factory building. Then a man came out of the factory and gave me a string of hemp. He advised me to enter the doorway because the sun was very hot already.
When I was repairing my strap, there was a flash. I was blinded for a moment because the light was so strong, as if the sun or a fireball had fallen down over my head. I couldn’t tell where it came from – side, front or behind. I didn’t know what had happened to me. It felt like I was mowed down, pinned or veiled in by something very strong. I couldn’t exhale.
I cried out: “I can’t breathe! I’m choking! Help me!” I fainted. It all happened in a matter of seconds. I heard something rustling nearby and suddenly recovered my senses. “Help me. Help me,” I cried.
A man wearing what seemed like an apron, tattered gaiters and ammo boots came towards her and called out: “Where are you? Where are you?” He pushed aside the debris and extended his arm to Yamanaka:
When I caught his hand, the skin of his hand stripped off and our hands slipped. He adjusted his hand and dragged me out of the debris, grabbing my fingers … I felt a sense of relief, but I forgot to say thank you to him. Everything happened in a moment.
Yamanaka started to run back the way she had come along the river, as “the city was not yet burning”. She saw the shrine just beyond Sumiyoshi bridge, not far from the river. But the bridge had been damaged by the bomb, so she couldn’t cross it.
Yamanaka’s family home was at Eba across the river. In those days, the River Ota was used for river transport and business, and there were huge stone steps going down to the river for loading. She said:
I wanted to get across to the other side. Then the city started to burn: the fires were chasing me and I had to run along the riverbank. I had to keep running as fast as possible until I finally reached Yoshijima jail. I was so scared but the area was not burning yet. I felt so relieved, I lost my consciousness.
She awoke hearing shouts of “is there anyone who is going back to Eba from Funairi?” and recognised a neighbour. She asked him to take her across, but he couldn’t recognise her. “I shed big tears when I heard his voice,” she told me. There were about ten people in a small wooden boat, all with “big swollen grotesque faces and frizzy hair. I thought they were old people. Maybe I also looked like an old woman,” she added.
After crossing the river in the small boat, Yamanaka ran to her Eba home which, even though it was 3km from ground zero, had collapsed. She couldn’t find her mother. Someone told her to go to the air-raid shelter nearby, but there were too many people to fit inside.
When she finally found her mother, she was barely recognisable, wrapped in bandages from her injuries. Yamanaka herself had to go to hospital as tiny pieces of glass from the factory windows where she had been exposed were lodged in her body.
She told me how some shards of glass still emerge from her body occasionally, secreting a chocolate-coloured pus. The family – Yamanaka, her mother and her younger brother (her father, grandparents and the other siblings had remained evacuated) – stayed up all night in a shelter on Eba hill, listening to the sounds of the burning city, the cries for mothers, the sounds of carts filled with refugees.
“All those sounds horrified me,” Yamanaka recalled – decades on from the day that changed everything.
The aftermath of the atomic bomb showing the former Hiroshima Industrial Promotion hall. The Peace Memorial Park, dedicated to the victims, would later be built here. Shutterstock/CG Photographer
The day the world changed
The immediate effects of the bomb, including heat, blast and radiation, extended to a 4km radius – although recent studies show the radioactive fallout from “black rain” extended much further, due to the winds blowing the mushroom cloud. And some survivors told me they witnessed the blast effects of the bomb, including windows blown out or structures disturbed, in outlying towns and villages up to 30km away.
But the closer you were to ground zero, the more likely you were to suffer severe effects. At 0.36km from ground zero, there was almost nothing left; about 4km away, 50% of the inhabitants died. Even 11km away, people suffered from third-degree burns due to the effects of radiation. The neutron rays also penetrated the surface of the earth, causing it to become radioactive.
The mushroom cloud was visible from the hills of neighbouring prefectures. Those who were beyond the immediate blast radius may not have shown any external injuries immediately – but they commonly became sick and died in the days, weeks, months and years that followed.
And those outside the city were exposed to radiation when they tried to enter to help the injured.
Radiation also affected children who were in the womb at the time. Common radiation-related diseases were hair loss, bleeding gums, loss of energy (“no more will” in Japanese) and pain, as well as life-threatening high fever.
About 650,000 people were recognised by the Japanese government as having been affected by the atomic bombings of Hiroshima and Nagasaki. While most have now passed away, figures held by the Ministry of Labour, Health and Welfare from March 31 2025 show there are an estimated 99,130 still alive, whose average age is now 86.
In a radio broadcast following the atomic bombings, Emperor Hirohito announced Japan’s surrender and called on the Japanese people to “bear the unbearable”, referring to the “most cruel weapons” that had been used by the Allied forces without directly identifying the nuclear attack. Due to ill-feeling about the defeat, shame over Japan’s imperial past and role in the war, plus censorship and ignorance about the reality of nuclear weapons, the idea grew that the dead and injured hibakusha were simply “sacrifices” (‘生贄 になる’) for world peace.
Generations affected
It took Yamanaka around seven years to recover her strength enough to lead a relatively normal life, so she barely graduated from high school. She has subsequently been diagnosed with various blood, heart, eye and thyroid diseases as well as low immunity – symptoms that can be related to radiation exposure.
Her daughters also suffered. In 1977, when her eldest daughter was 19, she had three operations for skin cancer. In 1978, when her second daughter was 14, she developed leukaemia. In 1987, her third daughter suffered from a unilateral oophorectomy (a surgical procedure to remove one ovary).
I interviewed Yamanaka’s daughters, granddaughter and several other survivors repeatedly, beginning with experiences prior to the atomic bombing and then continuing up to the present day.
While these interviews generally started in the official location of the Hiroshima Peace Memorial Museum, I also conducted walking interviews and went to sites of special importance to their personal memories. I shared car journeys, coffees and meals with them and their helpers, because I wanted to see their lives in context, as part of a community.
Their trauma and suffering are dealt with socially. For the relatively few survivors who tell their stories in public, it is through the help of strong local networks. While I was at first told I would not find survivors who wanted to share their stories, gradually more came forward through a snowball effect.
Returning to interview Yamanaka in August 2013, we travelled by car to her former home of Eba, pausing at the site where she had alighted after her journey across the river. There, Yamanaka struck up conversation with a fellow survivor who was passing on his bicycle. His name was Maruto-San. They had attended the same temple-based elementary school.
Emiko Yamanaka meets a fellow hibakusha, Maruto San, on a visit to her hometown in Eba with the author in August 2013. Elizabeth Chappell
The two hibakusha, who had both been exposed when young (part of a category known as jakunen hibakusha) exchanged stories about their experiences after “that day” (ano hi) – as August 6 and 9 are still known in the atomic-bombed cities.
They talked about how just one or two friends were still alive – one survivor ran a well-known patisserie in the local department store. Yamanaka informed Maruto-San that she had met a few friends from childhood on a reunion coach trip, during which they had tried to retrieve some happier pre-bomb memories. The meeting offered a rare glimmer of recognition and reconnection.
Keisaburo Toyanaga’s story
In 2014, I travelled to the childhood home of hibakusha Keisaburo Toyanaga, a retired teacher of classical Japanese who was nine on August 6 1945. After visiting his original home in east Hiroshima, we took the route he, his mother, grandfather and three-year-old younger brother had travelled, fleeing Hiroshima towards his grandfather’s house in the suburb of Funakoshi, about 8km away. He told me:
I remember coming this way on that day … My family was just one of many others, we were all travelling with our belongings on push-carts.
The family set up home in this poor suburb, which was shared with many Korean families who could not find a way out of poverty due to historic discrimination. Korea was annexed by Imperial Japan, and Koreans had been recruited en masse into Japan’s war effort. An estimated 40,000-80,000 were in Hiroshima in 1945.
Some high-ranking Koreans were accepted by the Japanese – for example, royals like Prince Yi U who was said to have been astride his horse at the time of the bombing. But ordinary Koreans had to refrain from using their language or wearing Korean clothes in public. Even after the war was over, they needed to use Japanese names outside the home. After the war, Koreans in Hiroshima took menial agricultural work – in Funakoshi, they kept pigs.
Confronted with discrimination in the classroom where he taught at the Electricity Workers’ school, Toyanaga became a campaigner for the right of repatriated South and North Koreans to be officially recognised as hibakusha from the 1970s onwards. He showed me the wooden talisman he wore around his neck, awarded by the Korean community for his support.
The author (far right) with Keisaburo Toyanaga (far left) and Keiko Ogura, both hibakusha, at the Hiroshima Peace Memorial Museum library in 2014. Elizabeth Chappell
The ghosts of Hiroshima
When I was living and working in Japan from 2004, before I started my academic research, I was advised to stay away from the atomic-bombed cities because speaking of the atomic bombings was considered “kanashii” (悲しい) “kowai” (怖い) and “kurushimii” (苦しみい) – sad, scary and painful. Some Japanese friends even expressed horror when I first went to Hiroshima and Nagasaki to do research. They seemed to feel it was like an act of self-harm. A young student I met warned me that the ghosts of the victims of Hiroshima rise at night to take over the city.
On my first visit in 2009, I stayed for one night in a youth hostel beside the railway tracks and the Hiroshima Carp baseball stadium. That night, a friend and I went for a drink with a couple, both second-generation hibakusha or “hibaku nisei”.
This couple, Nishida San and his wife Takeko, were involved in organising the annual Hiroshima Peace Memorial ceremony. Takeko sang in a choir that had been involved in several exchange visits to Europe, including visiting Notre Dame in Paris and Christ Church Cathedral in Oxford.
She said her parents had never told her about their experiences of the bomb, even though her father had been exposed close to ground zero. I was surprised to discover that hibakusha were reluctant to share their stories even within their own families, often for fear of physical and psychological harm being passed through the family line.
After our meeting in the bar, we went to eat okonomiyaki (“delicious food”), a pancake with cabbage, egg, pork and noodles, in a building known as “okonomiyaki mura” or okonomiyaki village. To me, it recalled a New York tenement block with an outdoor staircase serving as the entrance to all floors – the outlines of unbuilt rooms decorating its temporary facade. Such temporariness had lasted from the 1950s when concrete blocks like these went up around the city centre to service a whole new population after Hiroshima’s near-erasure. Since 1945, most inhabitants come from outside the city.
‘Flash … boom’
I was sitting with Nishida San on makeshift bar seats in front of a counter with a huge, heated iron plate. The chef, Shin San, took our order and as we chatted, one of our Hiroshima friends asked him if he remembered the atomic bomb. Shin replied: “Of course I do.”
Then he spread his arms wide and a strange expression appeared on his face, as he said: “Pikaaaaa… doon.” This translates as “flash… boom” – two onomatopoeic words that encapsulate so much for Hiroshima people. Many survivors, especially those downtown, only experienced the flash. Others, usually at some distance, experienced the sonic boom. So these two words were used in place of “gembakudan” (原爆弾) – meaning atomic bomb – due to censorship.
Nobel prize-winning author Kenzaburo Ōe, in his 1981 work Hiroshima Notes, wrote, ‘For 10 years after the atomic bomb was dropped there was so little public discussion of the bomb or of radioactivity that even the Chugoku Shimbun, the major newspaper of the city where the atomic bomb was dropped, did not have the movable [kanji] type for the words “atomic bomb” or “radioactivity.”’ To support this, I noticed how some monuments for those who died in downtown Hiroshima bear the simple inscription E=MC², Einstein’s formula for relativity – the source of the science that created the bomb, but not the actual words for “atomic bomb”.
Keiko Ogura: ‘40 years of nightmares’
The older generation often told me how they dreaded visiting the Hiroshima Peace Memorial Museum and its surrounding park, as they are built over ground zero. However, some found that after encountering visiting foreigners there who had also experienced mass suffering, such as the Holocaust or a nuclear test, they were more able to open up.
Keiko Ogura, now aged 87, was eight on August 6 1945 and was exposed to black rain at her home in Ushitamachi, 5km from the centre of Hiroshima. She said:
For 40 years, I had nightmares and did not want to tell the story. Growing up, our mothers did not speak of the atomic bombing as they were afraid of discrimination and prejudice. Getting older, we started to worry about our children and grandchildren’s health. After the Atomic Bomb Casualty Commission was established in 1947, some people expected to be cured of ABI [atomic bomb injury] … but in fact, the doctors there were just gathering blood and data.
Ogura had thought, as a child, that she would never find a partner due to the discrimination against hibakusha, but she was also acutely aware that other survivors had suffered more than her.
The author outside Mitaki Temple with Keiko Ogura (left) and Shoko Ishida in November 2013. Elizabeth Chappell
However, when Robert Jungk, a Holocaust survivor, came to research his book Children of the Ashes with the help of Kaoru Ogura – a bilingual American who had been interned during the second world war and would become Keiko’s husband – things started to shift for her. Finding out about the Holocaust lent a new dimension to her own experiences of discrimination.
Jungk – along with Robert J. Lifton, a genocide historian – wrote their interview-based studies of Hiroshima in the 1950s and ‘60s, when ordinary citizens around the world were largely ignorant of the enormity of what had happened in Hiroshima, Nagasaki and the nuclear test sites. Lifton, originally a military psychiatrist, explained that after the 1962 Cuban missile crisis, he had been motivated to study in Hiroshima as he was afraid the world was in danger of “making the same mistake again”.
However, the link between Hiroshima and the Holocaust was first made by Otto Frank, Anne Frank’s father, who organised for an Anne Frank rose garden to be planted in the Peace Memorial Park in honour of an 11-year-old girl, Sadako Sasaki, who died from leukaemia nine years after the bomb.
One autumnal afternoon in 2013, after my third round of interviews with my cohort of hibakusha, I visited Mitaki Temple Cemetery, about 6km outside Hiroshima. The graveyard is dedicated to hibakusha, many of whose ashes are kept there. The hibakusha headstones are engraved with haiku written by family members. However, many of the headstones which existed prior to 1945 have been left at jagged angles – positioned as they were after being upset by the seismic effects of the atomic bombing.
In among the recent graves, I was shown some Jewish hanging mobile memorials – gifts from Oświęcim in Poland, location of the Auschwitz concentration camp. The temple’s former head priest had been involved in the Hiroshima-Auschwitz Peace Committee, an interfaith group which had started with a walk around the world to link atomic bomb survivors with Holocaust and other war victims.
Making the connection was important to hibakusha who were accused, then as now, of highlighting the atrocities of the bomb but downplaying the importance of Japan’s role in the war. When visiting Japan’s former colonies and elsewhere, hibakusha still offer apologies for Japanese behaviour in the second world war.
For institutions in Hiroshima, it’s important to change the narrative around nuclear weapons – not only through more and better medical research, but by disseminating hibakusha stories. The local newspaper, Chugoku Shimbun, aims to strengthen informal networks of hibakusha who meet up to share memories of that day. Some local journalists I met, Rie Nii and Yumi Kanazaki, help young people to interview their grandparents’ generation, building up a valuable archive of experiences.
There are two ways the younger generation can carry these stories forward: either by training as denshōsha (ambassadors) or by interviewing family members.
Kazumi Kuwahara decided to do both. When she was just 13, she wanted to pass on her grandmother’s story, becoming the winner of a prefecture-wide speaking competition about the bomb. In her 20s, after graduating from university, she also decided to train as a denshōsha and peace park guide, a role that requires intensive training over a six-month period. As the youngest guide to the Hiroshima Peace Park, she says:
Each visitor has a unique nationality and upbringing and, as I interact with them, I constantly ask myself how best to share Hiroshima’s significant history.
Toward the end of my field work, having gained interviews with three generations of survivors as well as their helpers, I realised this was just the beginning of a much larger conversation.
John Hersey, author of the Pulitzer-prize winning 1946 work Hiroshima, said: “What has kept the world safe from the bomb since 1945 has been the memory of what happened at Hiroshima.”
However, as our memories get more spotty with the passing of time, and as more survivors’ names are added to the roll of the dead at the cenotaphs of Japan’s atomic-bombed cities, perhaps our greatest hope is to grow the cohort of today’s listeners – so that tomorrow’s storytellers may emerge.
To hear about new Insights articles, join the hundreds of thousands of people who value The Conversation’s evidence-based news. Subscribe to our newsletter.
Elizabeth Chappell does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
The feelings that surged through the pub that I watched the women’s Euro 2022 cup final in were electric. England had won. My friends were in tears. Strangers were shaking hands, patting each other on the back, smiling goofily at anyone who would catch their eye. It was wonderful. I’m hoping for repeat scenes this Sunday when the Lionesses face Spain in the 2025 Uefa European Women’s Championship.
Whether they win or not, the journey has been a joy. I watched the quarter-final between England and Sweden at a pub hosting an Irish trad folk night. With every England goal, the fiddlers celebrated with a rowdy song. The street I was watching the semi-final on erupted as different pockets of fans celebrated as Chloe Kelly scored the goal that would send the Lionesses into the final.
Women’s football has gone from strength to strength since that monumental win in 2022. Many of the Lionesses are now household names (Kelly, Lucy Bronze, Ella Toone and Beth Mead to name a few). As someone who attends women’s games, I’ve never seen the stands so full. You’ve also never been able to see so many games broadcast.
The situation for players has also massively improved with female footballers earning more than ever. In this piece, sports financing expert Christina Philippou, celebrates these many wins but also highlights where there is room for improvement.
A lot of the gains made in women’s football in England can be attributed to that win in 2022. Here’s hoping that on Sunday we see another win, which leads to many more strides for women’s football.
The 2025 Uefa European Women’s Championship final will be available to watch on the BBC at 5pm, July 27.
On Sunday, the Lionesses will march onto the pitch wearing their all-white home kit. The purpose of such clothing is to unite the players, to show they are a team and representatives of a country. In this, we can see how, as the philosopher Kate Moran writes in her new book, clothes are much more than just what we put on.
In A Philosopher Looks at Clothes, Moran shows that what we choose to wear is a worthy topic of deep philosophical inquiry.
Our reviewer, Sarah Richmond, a philosophy expert, found the book an engaging and unpretentious exploration of an ubiquitous aspect of daily life. Clothing provides Moran with fertile ground for ethical, political, aesthetic and identity-related reflections.
Also challenging how we have historically seen things is the new book by writer and curator Alayo Akinkugbe. In Reframing Blackness, Akinkugbe invites the reader to challenge art history and its approach to blackness.
How has the teaching of art history excluded blackness? How does such teaching then affect the creation and curation of art in relation to blackness.
Wanja Kimani, a curator herself, found the book engaged with many of the issues that black artists and those teaching and working in the arts have been grappling with since at least the 1960s in a clear-eyed and refreshingly optimistic manner.
For at least the last ten years there has been a growing trend for exhibitions that tackle climate change and the collapse of nature. Pandora Syperek, an expert in design, and Sarah Wade, an expert in museums, have been great supporters of the ability of such curation to communicate the urgency of such issues.
Putting their research into practice, the pair have put on their first exhibition entitled Sea Inside. Asking the question “can the sea survive us?” the show features art works that show how connected humanity is to the ocean.
These works are, as they write, emotive, imaginative and often very funny. From an aquarium full of tears to videos of jelly fish having sex in a lab, these works hope to move us closer to a care and understanding for fragile sea ecosystems.
Sea Inside is on at Sainsbury Centre in Norwich until 26 October, 2025
At The King’s Gallery, Buckingham Palace you can explore the glamour of the Edwardian age through some of Britain’s most fashionable royal couples – King Edward VII and Queen Alexandra, their son George V and his wife Mary of Teck.
As our reviewer, professor of modern British history Jane Hamlett notes, one of the most interesting things about The Edwardians: Age of Elegance is what it reveals about the personal taste of the royals. Featuring more than 300 objects from the Royal Collection – almost half for the first time – it is fascinating to see what they chose to collect. You’ll get the chance to see work by recognisable artists of the period, including Carl Fabergé, John Singer Sargent and William Morris.
This article features references to books that have been included for editorial reasons, and may contain links to bookshop.org. If you click on one of the links and go on to buy something from bookshop.org The Conversation UK may earn a commission.
Source: The Conversation – UK – By Natasha Lindstaedt, Professor in the Department of Government, University of Essex
As climate change drives rising temperatures and changes in rainfall, Mexico and the US are in the middle of a conflict over water, putting an additional strain on their relationship.
Partly due to constant droughts, Mexico has struggled to maintain its water deliveries for much of the last 25 years, in keeping with a water-sharing agreement between the two countries that has been in place since 1944 (agreements between the two regulating water sharing have existed since the 19th century).
As part of this 1944 treaty, set up when water was not as scarce as it is now, the two nations divide and share the flows from three rivers (the Rio Grande, the Colorado and the Tijuana) that range along their 2,000-mile border. The process is overseen by the International Boundary and Water Commission.
Mexico must send 430 million cubic metres of water per year from the Rio Grande to the US, while the US must send nearly 1.85 billion cubic metres of water from the Colorado River to support the Mexican border cities of Tijuana and Mexicali.
Water deliveries are measured over a five-year cycle, and the current one ends in October. Mexico struggled to deliver its water “debt” in the last cycle which ended in 2020, using waters from reservoirs at the last minute to fulfil its obligations. This left northern Mexico with severely depleted water levels.
Due to growing tensions over water, the Biden administration tried to negotiate and work with the Mexican government to improve the speed with which Mexico’s water deliveries were taking place in 2024.
But with Donald Trump’s return to office, the US has taken a more aggressive stance with Mexico to address its water debts to the US. For the first time in over 50 years, in March of 2025, the US refused to send water from the Colorado River to Tijuana – a city of nearly 2 million people – in order to force Mexico to send more water to Texas.
Mexico has since responded by transferring 75 million cubic metres of water, but this is just a drop in the bucket, as Mexico remains 1.5 billion cubic metres in debt. And this did little to satisfy the Trump administration, which threatened to withhold more water from Mexico. It also demanded the resignation of Maria-Elena Giner, who led the International Boundary and Water Commission, in April.
Rather than looking at diplomatic solutions, Trump has accused Mexico of stealing Texans’ water and has promised to keep escalating consequences if it doesn’t deliver on the treaty terms.
For farmers in Texas, the water shortage has left them unable to plant their crops as they don’t have enough irrigated water to do so. A year ago, the last sugar mill in southern Texas shut down due to the lack of water being delivered by Mexico.
But Mexican farmers believe that the agreement is binding only when Mexico has enough water to satisfy its own needs – and with drought conditions, this means that no excess available water can be sent. Continuing drought conditions in Mexico have plagued farmers in the north, who also rely on water for their crops. Reductions in rainfall in recent years have also left Mexico struggling with water supplies for its own citizens in urban areas.
In recent years, drought has particularly affected the city of Monterrey in northern Mexico. In 2022, taps ran dry with many of its five million residents without running water for months. Flushing toilets, laundering clothing, washing dishes, bathing all required hauling water by hand from wells.
Locals protested the fact that the best water infrastructure went to factories, not residents. One factor is that water demand has skyrocketed due to more manufacturing in border cities in Mexico.
While increased manufacturing poses one problem, an even bigger problem lies with agriculture, and the types of plants being planted, as well as the way they have traditionally been watered. For example, avocados require 91 litres a day – four times more water than the production of oranges, and ten times more than the production of tomatoes.
Alfalfa is another thirsty crop being mass produced in drought-prone states, such as Texas, California and even Arizona.
Citizens in Mexico City sometimes faced weeks of water shortages in recent years.
As much as 80% of the Colorado River basin’s water is used for agriculture and about half of that goes towards the production of alfalfa. Even more concerning is that most of the water is going to feed these thirsty crops. And in the dry south-west states of the US half of its water goes to towards the production of beef and dairy cattle.
This has an impact on cities who are completely dependent on the Colorado River. In the case of Tijuana in Mexico, the Colorado River supplies 90% of its water, while US cities such as Los Angeles and Las Vegas receive 50% and 90% of their water supplies from the Colorado River and basin, respectively.
This is a major concern as both the Colorado River and the Rio Grande are experiencing record low levels of water. And getting more water from Mexico is not a long-term solution.
Though the Biden administration was criticised by farmers for not threatening Mexico, by withholding water, its approach largely focused more on the long-term challenges.
For the previous US administration the solution was to invest more in the Colorado River basin, incentivising California, Arizona and Colorado to conserve three million acre-feet of water through 2026 in return for US$1 billion (£741,000,000) in federal funding.
What drives this conflict?
But under Trump, federal funding for tackling climate change is being slashed. Increased polarisation in US domestic politics and growing tensions between the US and Mexico will make resolving this crisis all the more difficult.
This is a missed opportunity. Even though conflicts over water are becoming more frequent, water scarcity can also be a potential driver of cooperation.
Meanwhile, the US’s relationship with Mexico continues to be rocky. Trump has threatened to put new 30% tariffs on Mexico from August 1, after he claimed it hadn’t done enough to tackle drug cartels.
Mexico’s president, Claudia Sheinbaum, has said her government was destroying drug laboratories every day, and that the US must control weapons travelling over its border into Mexico which were being used for criminal purposes. Meanwhile, high tariffs on Mexican goods are likely to affect US consumers as Mexico is currently the US’s biggest trading partner.
Cooperation, and acknowledging the role played by climate change, and unsustainable forms of development in both agriculture and manufacturing are key to resolving this cross-border water crisis – but these are things that the Trump administration is unlikely to acknowledge, or address.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Natasha Lindstaedt does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
The first Welsh settlers landed on the shores of what is today the Province of Chubut, in Argentinean Patagonia, on 28 July 1865. Carried on the ship Mimosa, this was the first of a series of immigrant contingents to create the Welsh settlement known as Y Wladfa.
The many chronicles and accounts about it have imbued the settlement with a mythical sheen. Today, Y Wladfa is home to the most famous Welsh-speaking community outside Wales. It is often touted in Britain as a little Wales across the sea. In fact, “Welsh Patagonia”, as it’s also known, was established precisely with the aim of preserving the language and culture.
A major aspect of the settlement that is celebrated is the unique friendship with the Indigenous Tehuelche that the Welsh immigrants would have struck up. However, with the commemoration of 160 years of that first group of settlers, the story about this connection is being challenged in a recently launched digital exhibition: Problematising History: Indigenous perspectives on Welsh settlement in Patagonia.
Looking for something good? Cut through the noise with a carefully curated selection of the latest releases, live events and exhibitions, straight to your inbox every fortnight, on Fridays. Sign up here.
Rather than attempting to undo the past, the project aims to address a glaring omission in historical accounts which results in an incomplete understanding of the impacts of the settlement – the lack of indigenous perspectives.
The new trilingual (Spanish, Welsh and English) exhibition challenges romanticised views about the myth of friendship between the Welsh settlers and the Indigenous Tehuelche in Patagonia. Bringing together four Mapuche Tehuelche creative projects, it reflects critically on how the story of Welsh colonisation in Chubut is told by providing a platform for voices previously unheard in Britain.
Little Wales across the sea
In Welsh Patagonia you can see quaint casas de té gales (Welsh tea houses), the ever-present dragons and strangely familiar Welsh street names. You will also see the Welsh language in towns like Gaiman, Trevelin or Trelew. To find a language that is only spoken by less than 20% in Wales itself be so present in this corner of Latin America can make for an odd experience.
The stories of how this place came to be are typical of settler colonial settings. These rose-tinted tales describe the encounter between the Welsh and the Indigenous Tehuelche as a harmonious meeting of cultures that led to a lasting friendship. The assumption is that the largely peaceful coexistence was due to the inherent Welsh benevolence rather than the result of negotiation and relationship building on both sides.
The overlooking of Indigenous agency and resistance is partly due to virtually all of the historical records available in Welsh or English being created by Welsh or European people. Even those appearing to foreground indigenous voices were recorded by non-Indigenous rapporteurs and often include at least one layer of translation.
As voices in the project Puel Willi Mapu Mew: Taiñ Zungun have said about the “Welsh rifleros” (the first Welsh explorers to “go West”):
“Their arrival is commemorated as an epic legend and they are inscribed as heroes who ‘discovered’ our land, silencing our pre-existence as Tehuelche Mapuche people, and leading to the violence of the successive evictions and removals of our lof (community).”
The incorporation of indigenous perspectives on Welsh settlement to the collections of the National Library of Wales represents a groundbreaking development. It is about time that space has been made for Mapuche Tehuelche memories about forced displacement, territorial dispossession and heritage appropriations.
Changing perceptions
The early pioneers were invited by the Argentinean government to settle in the area around the Chubut river. They were then pretty much left to their own devices to endure in the unforgiving and harsh terrain. The Indigenous Tehuelche would have not only provided them with meat but taught them to hunt and survive in their new environment.
An aspect of that good will can be traced to the Chegüelcho agreement, which the Argentine government drew up with the leaders of local Indigenous communities. The agreement stipulated that, provided the Welsh settlement was left to develop on the lands in question, the central government would send regular rations to the communities and provide animals and clothing.
However, the nuances of the coexistence have been removed, leaving a flattened historical narrative. In reality, the relationship was the result of continuous renegotiation of practical necessities and pursuit of reciprocal benefit – but was also fraught.
The Welsh outpost was beneficial to Patagonian indigenous populations in providing a convenient outlet for trading their animal skins and ostrich feathers. However, Y Wladfa was the first step of a broader Argentine project that actively sought to dispossess indigenous peoples and assert state sovereignty over Patagonia.
“The official history of Chubut silences the stories of the Mapuche and allows words like ‘progress’ and ‘Welsh settlers’ to resonate,” contributor Agustín Pichiñan explains.
“With the support of the State, fences were extended all over our territory bringing us subjugation, harassment and discrimination. Yet, we keep on resisting and fighting to recover our history, using the knowledge of our ancestors and the memories of our lof (community).”
Sustaining a simplified historical narrative and ignoring indigenous perspectives allows convenient stories which simply celebrate Y Wladfa. It prevents us from sitting with uncomfortable truths and learning.
Chief among these truths is that as a colonised people themselves the Welsh were agents of colonialism elsewhere. This is part of the wider history of Patagonian settlement and is key to striving for a better present and future for all involved.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Geraldine Lublin has received funding for the “Problematising History: Indigenous perspectives on Welsh settlement in Patagonia”.project from the Arts & Humanities Research Council Impact Acceleration Account at Swansea University.
Source: The Conversation – UK – By Indranil Banik, Postdoctoral Research Fellow in Astrophysics, University of Portsmouth
Baryon acoustic oscillations represent the sound of the Big Bang. Gabriela Secara, Perimeter Institute, CC BY-SA
Looking up at the night sky, it may seem our cosmic neighbourhood is packed full of planets, stars and galaxies. But scientists have long suggested there may be far fewer galaxies in our cosmic surroundings than expected.
In fact, it appears we live in a giant cosmic void with roughly 20% lower than the average density of matter.
Not every physicist is convinced that this is the case. But our recent paper analysing distorted sounds from the early universe, published in the Monthly Notices of the Royal Astronomical Society, strongly backs up the idea.
Cosmology is currently in a crisis known as the Hubble tension: the local universe appears to be expanding about 10% faster than expected. The predicted rate comes from extrapolating observations of the infant universe forward to the present day using the standard model of cosmology, known as Lambda-Cold Dark Matter (ΛCDM).
We can observe the early universe in great detail through the cosmic microwave background (CMB), relic radiation from the early universe, when it was 1,100 times smaller than it is today. Sound waves in the early universe ultimately created areas of low and high densities, or temperatures.
By studying CMB temperature fluctuations on different scales, we can essentially “listen” to the sound of the early universe, which is especially “noisy” at particular scales.
These fluctuations are now imprinted in the CMB, and dubbed “baryon acoustic oscillations” (BAOs). Since these became the seeds for galaxies and other structures, the patterns are also visible in the distribution of galaxies.
By measuring these patterns, we can learn how galaxies are clustered at different redshifts (distances). A particularly striking pattern, with lots of clustering, occurs at an angle called the “angular BAO scale”.
Illustration showing that slightly more galaxies formed along the ripples of the primordial sound waves (marked blue) than elsewhere. Then the rings of galaxies stretched with the expansion of the universe. Other galaxies are dimmed in this image to make the effect easier to see. Nasa
This measurement ultimately helps astronomers and cosmologists learn about the universe’s expansion history by providing something physicists call a “standard ruler”. This is essentially an astronomical object or a feature on the sky with a well-known size.
By measuring its angular size on the sky, cosmologists can therefore calculate its distance from Earth using trigonometry. One can also use the redshift to determine how fast the cosmos is expanding. The larger it appears on the sky at a certain redshift, the faster the universe is expanding.
My colleagues and I previously argued that the Hubble tension might be due to our location within a large void. That’s because the sparse amount of matter in the void would be gravitationally attracted to the more dense matter outside it, continuously flowing out of the void.
In previous research, we showed that this flow would make it look like the local universe is expanding about 10% faster than expected. That would solve the Hubble tension.
But we wanted more evidence. And we know a local void would slightly distort the relation between the BAO angular scale and the redshift due to the faster moving matter in the void and its gravitational effect on light from outside.
So in our new paper, Vasileios Kalaitzidis and I set out to test the predictions of the void model using BAO measurements collected over the last 20 years. We compared our results to models without a void under the same background expansion history.
In the void model, the BAO ruler should look larger on the sky at any given redshift. And this excess should become even larger at low redshift (close distance), in line with the Hubble tension.
The observations confirm this prediction. Our results suggest that a universe with a local void is about one hundred million times more likely than a cosmos without one, when using BAO measurements and assuming the universe expanded according to the standard model of cosmology informed by the CMB.
Our research shows that the ΛCDM model without any local void is in “3.8 sigma tension” with the BAO observations. This means the likelihood of a universe without a void fitting these data is equivalent to a fair coin landing heads 13 times in a row. By contrast, the chance of the BAO data looking the way they do in void models is equivalent to a fair coin landing heads just twice in a row. In short, these models fit the data quite well.
In the future, it will be crucial to obtain more accurate BAO measurements at low redshift, where the BAO standard ruler looks larger on the sky – even more so if we are in a void.
The average expansion rate so far follows directly from the age of the universe, which we can estimate from the ages of old stars in the Milky Way. A local void would not affect the age of the universe, but some proposals do affect it. These and other probes will shed more light on the Hubble crisis in cosmology.
Get your news from actual experts, straight to your inbox.Sign up to our daily newsletter to receive all The Conversation UK’s latest coverage of news and research, from politics and business to the arts and sciences.
Indranil Banik receives funding from the Royal Society as part of a University Research Fellowship managed by his boss Harry Desmond. The second author on the paper was Vasileios Kalaitzidis, who received an undergraduate summer project grant from the Royal Astronomical Society to undertake the analysis described here.
As a scholar who examines the history of U.S. immigration law and enforcement, I believe that it remains far from clear whether the Trump White House will significantly reduce the undocumented population. But even if the administration’s efforts fail, the fear and damage to the U.S. immigrant community will remain.
Presidents Bush and Obama
To increase deportations, in 2006 President George W. Bush began using workplace raids. Among these sweeps was the then-largest immigration workplace operation in U.S. history at a meat processing plant in Postville, Iowa in 2008.
U.S. Immigration and Customs Enforcement deployed 900 agents in Postville and arrested 398 employees, 98% of whom were Latino. They were chained together and arraigned in groups of 10 for felony criminal charges of aggravated identity theft, document fraud and use of stolen Social Security numbers. Some 300 were convicted, and 297 of them served jail sentences before being deported.
In 2008, Bush also initiated Secure Communities, a policy that sought to deport noncitizens – both lawful permanent residents as well as undocumented immigrants – who had been arrested for crimes. Some 2 million immigrants were deported during Bush’s two terms in office.
The Obama administration limited Secure Communities to focus on the removal of noncitizens convicted of felonies. It deported a record 400,000 noncitizens in fiscal year 2013, which led detractors to refer to President Barack Obama as the “Deporter in Chief.”
Trump’s first administration broke new immigration enforcement ground in several ways.
He began his presidency by issuing what was called a “Muslim ban” to restrict the entry into the U.S. of noncitizens from predominantly Muslim nations.
Early in Trump’s first administration, federal agents expanded immigration operations to include raids at courthouses, which previously had been off-limits.
In 2019, Trump implemented the Remain in Mexico policy that for the first time forced noncitizens who came to the U.S. border seeking asylum to wait in Mexico while their claims were being decided. He also invoked Title 42 in 2020 to close U.S. borders during the COVID-19 pandemic.
Immigration-rights activists stage a rally outside President Barack Obama’s Democratic Congressional Campaign Committee fundraiser in Los Angeles, after the president signed a bill that tightened security at the Mexico border in August 2010. Mark Ralston/AFP via Getty Images
In January 2025, he announced an expanded, expedited removal process for any noncitizen apprehended anywhere in the country – not just the border region, as had been U.S. practice since 1996.
These issues have not been seriously addressed by any modern U.S. president. Until it is, we can expect the undocumented population to remain in the millions.
Kevin Johnson does not work for, consult, own shares in or receive funding from any company or organization that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Demographers generally gauge births in a population with a measure called the total fertility rate. The total fertility rate for a given year is an estimate of the average number of children that women would have in their lifetime if they experienced current birth rates throughout their childbearing years.
Fertility rates are not fixed – in fact, they have changed considerably over the past century. In the U.S., the total fertility rate rose from about 2 births per woman in the 1930s to a high of 3.7 births per woman around 1960. The rate then dipped below 2 births per woman in the late 1970s and 1980s before returning to 2 births in the 1990s and early 2000s.
But while the total fertility rate offers a snapshot of the fertility landscape, it is not a perfect indicator of how many children a woman will eventually have if fertility patterns are in flux – for example, if people are delaying having children.
Picture a 20-year-old woman today, in 2025. The total fertility rate assumes she will have the same birth rate as today’s 40-year-olds when she reaches 40. That’s not likely to be the case, because birth rates 20 years from now for 40-year-olds will almost certainly be higher than they are today, as more births occur at older ages and more people are able to overcome infertility through medically assisted reproduction.
A more nuanced picture of childbearing
These problems with the total fertility rate are why demographers also measure how many total births women have had by the end of their reproductive years. In contrast to the total fertility rate, the average number of children ever born to women ages 40 to 44 has remained fairly stable over time, hovering around two.
In other words, it doesn’t seem to be the case that birth rates are low because people are uninterested in having children; rather, it’s because they don’t feel it’s feasible for them to become parents or to have as many children as they would like.
The challenge of predicting future population size
Standard demographic projections do not support the idea that population size is set to shrink dramatically.
One billion people lived on Earth 250 years ago. Today there are over 8 billion, and by 2100 the United Nations predicts there will be over 10 billion. That’s 2 billion more, not fewer, people in the foreseeable future. Admittedly, that projection is plus or minus 4 billion. But this range highlights another key point: Population projections get more uncertain the further into the future they extend.
Predicting the population level five years from now is far more reliable than 50 years from now – and beyond 100 years, forget about it. Most population scientists avoid making such long-term projections, for the simple reason that they are usually wrong. That’s because fertility and mortality rates change over time in unpredictable ways.
The U.S. population size is also not declining. Currently, despite fertility below the replacement level of 2.1 children per woman, there are still more births than deaths. The U.S. population is expected to grow by 22.6 million by 2050 and by 27.5 million by 2100, with immigration playing an important role.
Despite a drop in fertility rates, there are still more births than deaths in the U.S. andresr/E+ via Getty Images
Will low fertility cause an economic crisis?
A common rationale for concern about low fertility is that it leads to a host of economic and labor market problems. Specifically, pronatalists argue that there will be too few workers to sustain the economy and too many older people for those workers to support. However, that is not necessarily true – and even if it were, increasing birth rates wouldn’t fix the problem.
As fertility rates fall, the age structure of the population shifts. But a higher proportion of older adults does not necessarily mean the proportion of workers to nonworkers falls.
For one thing, the proportion of children under age 18 in the population also declines, so the number of working-age adults – usually defined as ages 18 to 64 – often changes relatively little. And as older adults stay healthier and more active, a growing number of them are contributing to the economy. Labor force participation among Americans ages 65 to 74 increased from 21.4% in 2003 to 26.9% in 2023 — and is expected to increase to 30.4% by 2033. Modest changes in the average age of retirement or in how Social Security is funded would further reduce strains on support programs for older adults.
What’s more, pronatalists’ core argument that a higher birth rate would increase the size of the labor force overlooks some short-term consequences. More babies means more dependents, at least until those children become old enough to enter the labor force. Children not only require expensive services such as education, but also reduce labor force participation, particularly for women. As fertility rates have fallen, women’s labor force participation rates have risen dramatically – from 34% in 1950 to 58% in 2024. Pronatalist policies that discourage women’s employment are at odds with concerns about a diminishing number of workers.
Research shows that economic policies and labor market conditions, not demographic age structures, play the most important role in determining economic growth in advanced economies. And with rapidly changing technologies like automation and artificial intelligence, it is unclear what demand there will be for workers in the future. Moreover, immigration is a powerful – and immediate – tool for addressing labor market needs and concerns over the proportion of workers.
Overall, there’s no evidence for Elon Musk’s assertion that “humanity is dying.” While the changes in population structure that accompany low birth rates are real, in our view the impact of these changes has been dramatically overstated. Strong investments in education and sensible economic policies can help countries successfully adapt to a new demographic reality.
Leslie Root receives funding from the Eunice Kennedy Shriver National Institute of Child Health and Development (NICHD) for work on fertility rates.
Karen Benjamin Guzzo has received funding from the Eunice Kennedy Shriver National Institute of Child Health and Human Development in the United States.
Shelley Clark receives funding from the Social Sciences and Humanities Research Council of Canada.
I saw it firsthand after my cat Murphy died earlier this year. She’d been diagnosed with cancer just weeks before.
She was a small gray tabby with delicate paws who, even during chemotherapy, climbed her favorite dresser perch – Mount Murphy – with steady determination.
The day after she died, a colleague said with a shrug: “It’s just part of life.”
That phrase stayed with me – not because it was wrong, but because of how quickly it dismissed something real.
Murphy wasn’t just a cat. She was my eldest daughter – by bond, if not by blood. My shadow.
But when someone grieves them like family, the cultural script flips. Grief gets minimized. Support gets awkward. And when no one acknowledges your loss, it starts to feel like you weren’t even supposed to love them that much in the first place.
And I’ve seen firsthand how often grief following pet loss gets brushed aside – treated as less valid, less serious or less worthy of support than human loss. After a pet dies, people often say the wrong thing – usually trying to help, but often doing the opposite.
Psychologists describe this kind of unacknowledged loss as disenfranchised grief: a form of mourning that isn’t fully recognized by social norms or institutions. It happens after miscarriages, breakups, job loss – and especially after the death of a beloved animal companion.
The pain is real for the person grieving, but what’s missing is the social support to mourn that loss.
Even well-meaning people struggle to respond in ways that feel supportive.
And when grief gets dismissed, it doesn’t just hurt – it makes us question whether we’re even allowed to feel it.
Here are three of the most common responses – and what to do instead:
‘Just a pet’
This is one of the most reflexive responses after a loss like this. It sounds harmless. But under the surface is a cultural belief that grieving an animal is excessive – even unprofessional.
That belief shows up in everything from workplace leave policies to everyday conversations. Even from people trying to be kind.
Pets often become attachment figures; they’re woven into our routines, our emotional lives and our identities. Recent research shows that the quality of the human-pet bond matters deeply – not just for well-being, but for how we grieve when that connection ends.
What’s lost isn’t “just an animal.” It’s the steady presence who greeted you every morning. The one who sat beside you through deadlines, small triumphs and quiet nights. A companion who made the world feel a little less lonely.
But when the world treats that love like it doesn’t count, the loss can cut even deeper.
It may not come with formal recognition or time off, but it still matters. And love isn’t less real just because it came with fur.
If someone you care about loses a pet, acknowledge the bond. Even a simple “I’m so sorry” can offer real comfort.
‘I know how you feel’
“I know how you feel” sounds empathetic, but it quietly shifts the focus from the griever to the speaker. It rushes in with your story before theirs has even had a chance to land.
That instinct comes from a good place. We want to relate, to reassure, to let someone know they’re not alone. But when it comes to grief, that impulse often backfires. Grief doesn’t need to be matched. It needs to be honored and given time, care and space to unfold, whether the loss is of a person or a pet.
Instead of responding with your own story, try simpler, grounding words:
“You can always get another one” is the kind of thing people offer reflexively when they don’t know what else to say – a clumsy attempt at reassurance.
Underneath is a desire to soothe, to fix, to make the sadness go away. But that instinct can miss the point: The loss isn’t practical – it’s personal. And grief isn’t a problem to be solved.
This type of comment often lands more like customer service than comfort. It treats the relationship as replaceable, as if love were something you can swap out like a broken phone.
But every pet is one of a kind – not just in how they look or sound, but in how they move through your life. The way they wait for you at the door and watch you as you leave. The small rituals that you didn’t know were rituals until they stopped. You build a life around them without realizing it, until they’re no longer in it.
You wouldn’t tell someone to “just have another child” or “just find a new partner.” And yet, people say the equivalent all the time after pet loss.
Rushing to replace the relationship instead of honoring what was lost overlooks what made that bond irreplaceable. Love isn’t interchangeable – and neither are the ones we lose.
So offer care that endures. Grief doesn’t follow a timeline. A check-in weeks or months later, whether it’s a heart emoji, a shared memory or a gentle reminder that they’re not alone, can remind someone that their grief is seen and their love still matters.
When people say nothing
People often don’t know what to say after a pet dies, so they say nothing. But silence doesn’t just bury grief, it isolates it. It tells the griever that their love was excessive, their sadness inconvenient, their loss unworthy of acknowledgment.
And grief that feels invisible can be the hardest kind to carry.
So if someone you love loses a pet, don’t change the subject. Don’t rush them out of their sadness. Don’t offer solutions.
Instead, here are a few other ways to offer support gently and meaningfully:
Say their pet’s name.
Ask what they miss most.
Tell them you’re sorry.
Let them cry.
Let them not cry.
Let them remember.
Because when someone loses a pet, they’re not “just” mourning an animal. They’re grieving for a relationship, a rhythm and a presence that made the world feel kinder. What they need most is someone willing to treat that loss like it matters.
Brian N. Chin does not work for, consult, own shares in or receive funding from any company or organization that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.


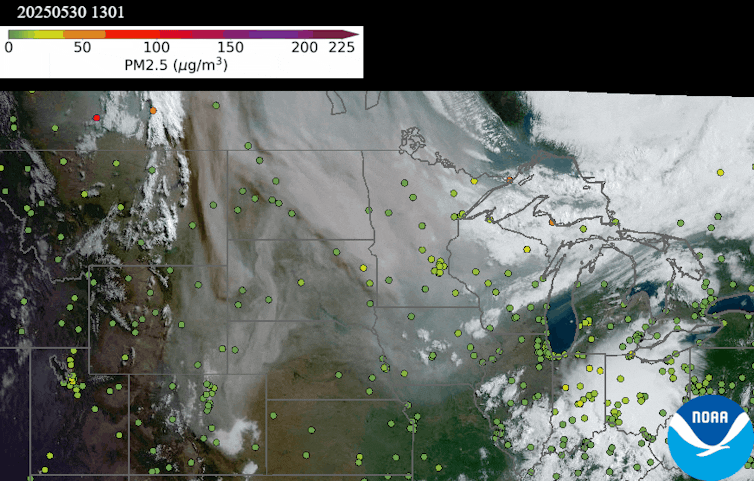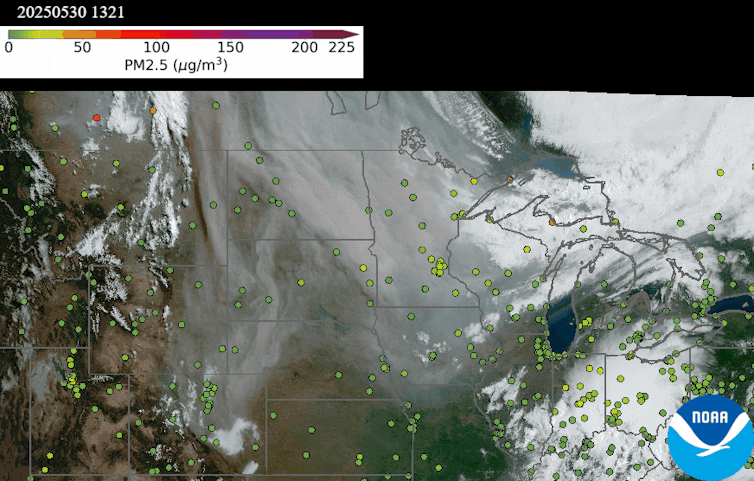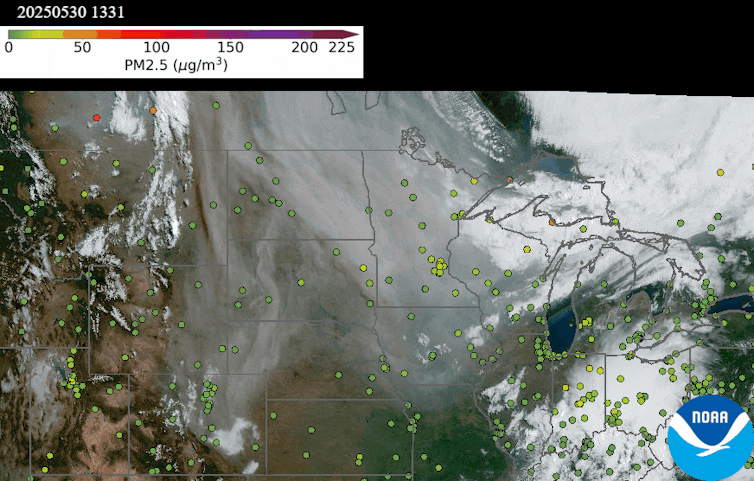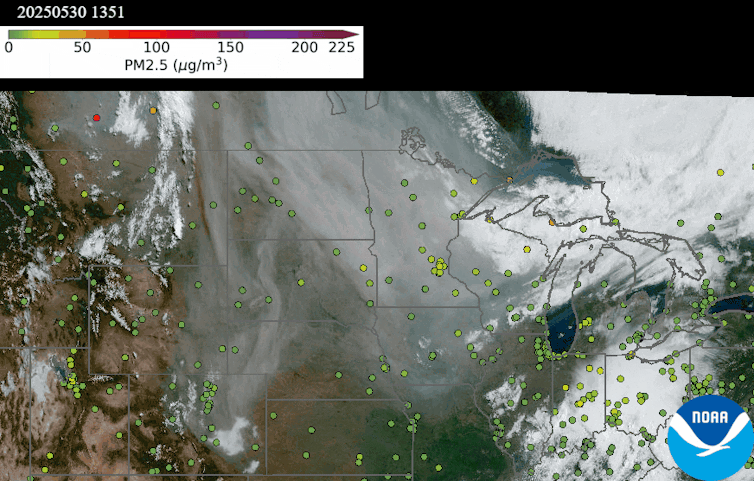

















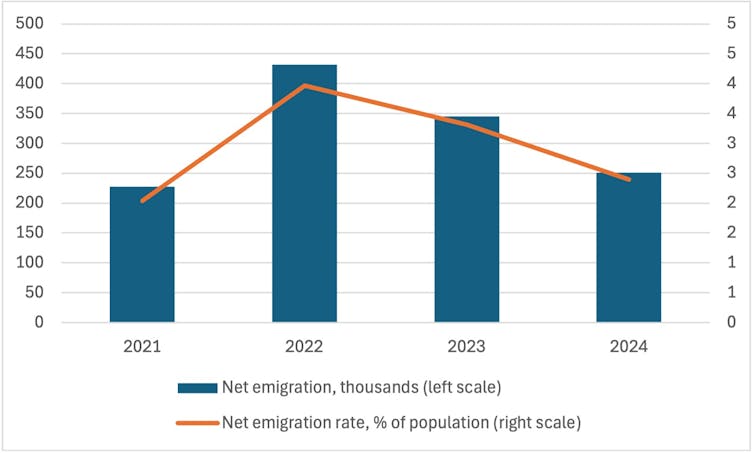
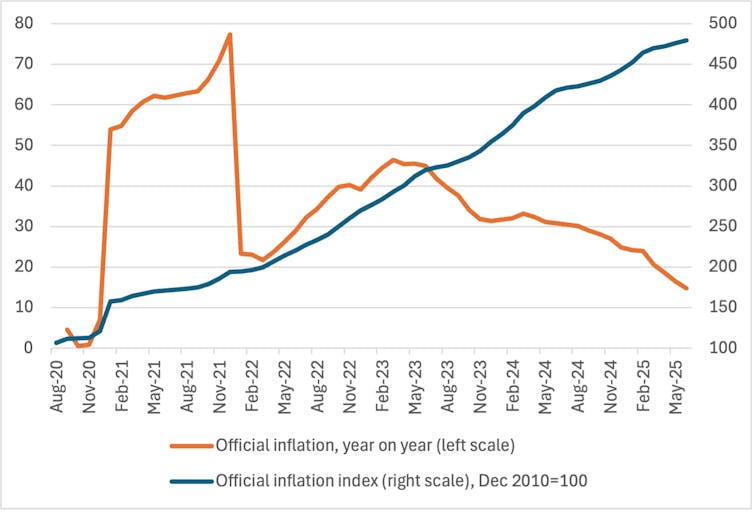





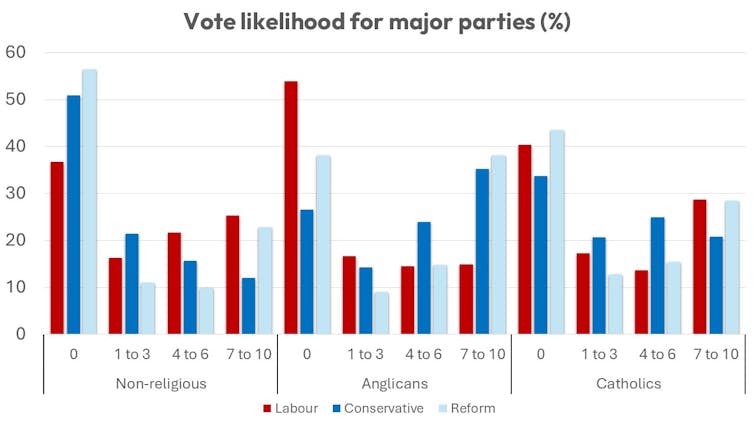
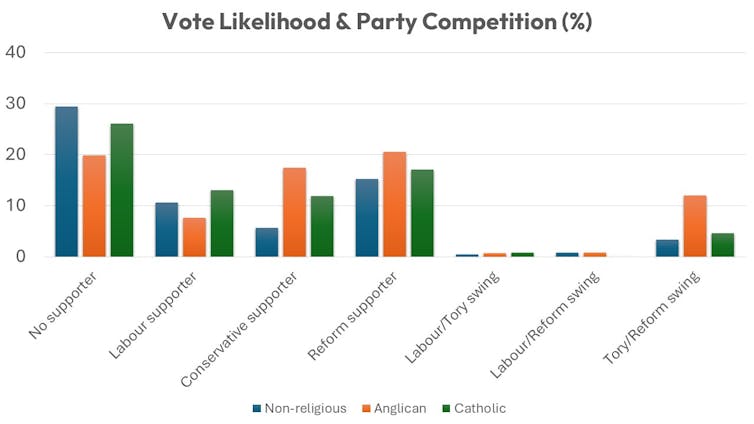



















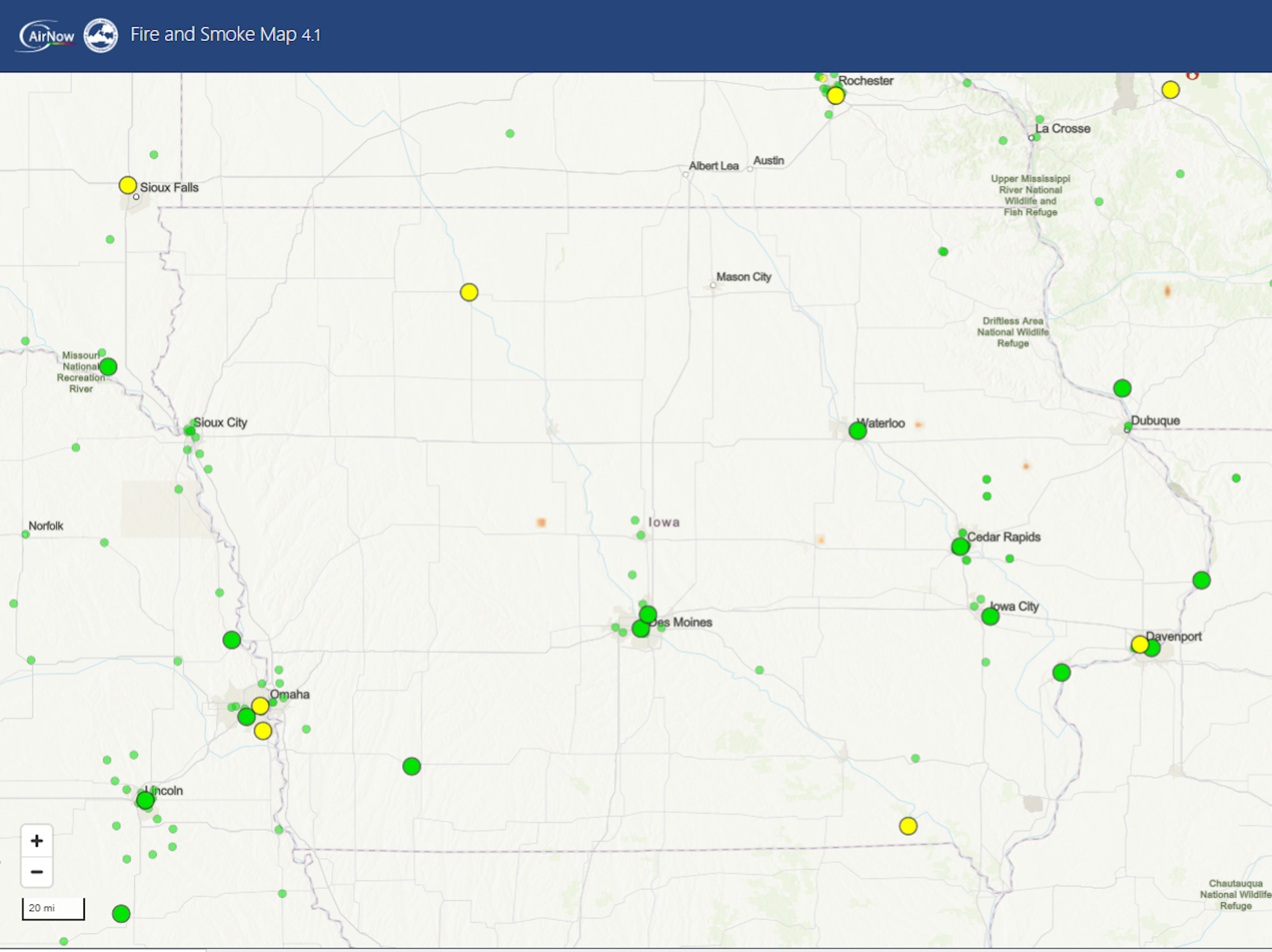{kind=link}
{kind=link}
{kind=link}
{kind=link}